Capitulo del libro: The Handbook of Video Databases: Design and Applications.
El objetivo de la investigación en la valoración objetiva de la calidad de imagen y video es diseñar métricas de calidad que puedan predecir automáticamente la calidad
de imagen o video percibidas.
Las métricas objetivas se pueden utlizar para:
- Monitorizar la calidad de imagen en sistemas de control
- Benchmarking de algoritmos y sistemas de procesamiento de video.
- Insertarse en sistemas de procesamiento de imagen y video para optimizar los algoritmos y establecer sus parametros.
Las Metricas de Valoración de la Calidad (MVC) se pueden clasificar de acuerdo a la disponibilidad de las imagenes o videos originales. Se asumen éstos libres
de distorsion para poderlos usar como referencia y compararlas con la señal procesada o distorsionada. Las metricas que comparan con el original se
denominan Full Reference Metrics (FR). Se habla de metricas de calidad de imagen o video cuando deberían
denomiarse metricas de fidelidad o similitud.
Las metricas que no disponen de la imagen de referencia se denominan "blind metrics" o No Reference Metrics (NR). Los
humanos realizamos la valoración de la calidad de la imagen o video distorsionados sin esfuerzo y sin referencia.
Existe otro tipo de metricas en las que la referencia no esta completamente disponible, pero si información acerca de ésta. Se extraen caracteristicas de la referenica
que son enviadas al sistema de evaluación de la calidad para compararlas con las de la resultante distorsionada.
Se denominan Reduced Reference Metrics (RR).
Actualmente las FR mas utilizadas son el MSE (Mean Squared Error) y el PSNR
(Peak Signal-to-Nooise Ratio) cuya definición muestra. Son muy usadas porque son
muy simples de calcular, de implementar, tratables matemáticamente (MSE es diferenciable). Sin embargo no muestran una buena correlación con la evaluación
subjetiva realizada por humanos. En las últimas decadas se introducen nuevas métricas que tienen en cuenta medidas perceptuales inspiradas en el HVS (Human Visual System).
Todavía no se tiene una metrica definitiva y estandar valida para todos los casos. De hecho los informes de las evaluaciones de esos sistemas
[10,11] reportan solamente un éxito relativo.
MSE no esta bien correlacionada con el sistema de percepción humana por:
- Los pixeles (unidad de procesamiento) pueden no representar estimulos luminosos entrantes en el ojo.
- La sensibilidad del HVS a los errores puede ser diferente en funcion del tipo de error.
- La cantidad de energia de error en dos imagenes puede ser la misma pero provenir de diferentes tipos de error.
- Un simple sumatorio de error no parece la forma en la que el HVS peciba la distorsión de la imagen o video.
La mayoria de las metricas FR estan basadas en la sensibilidad a los errores "Error Sensitivity Framework". Revisa las metricas FR basadas en este marco y propone
un nuevo marco de trabajo basado en la distorsion estructural de las imágenes. Luego revisa las metricas NR y RR.
Metricas FR que uitlizan medidas de sensibilidad de error.
Se puede asumir que la perdida de calidad esta relacionada con la fuerza de la señal de error. Una señal procesada tendrá referencia + error. Una aproximación a la
medida de calidad es medir y cuantificar el error entre la procesada y la referencia. Un trabajo pionero en la mejora de MSE con la inclusión de caracteristicas del
HVS es Manos y Sakrison [12] aunque para imagenes.
Anatomia del HVS
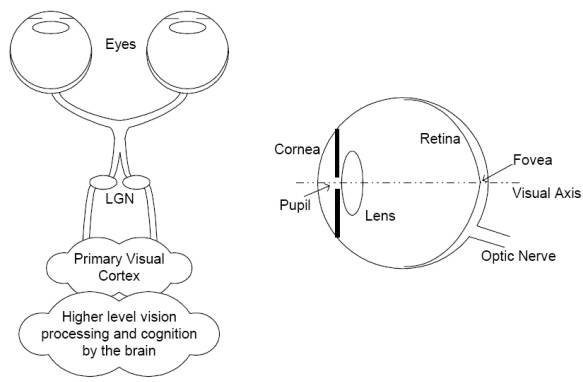
Realiza una revisión de la anatomia del HVS (Human Visual System) y las caracteristicas
psicofisicas y psicologicas que pueden ser utilizadas en las distintas métricas. El blur
(suavizado, hacer borroso) que se produce en la imagen por las imperfectiones del ojos es paso-bajo, modelado normalmente con una PSF (Point Spread Function)
invariante en el tiempo. El HVS no puede percibir el estímulo visual completo con una resolución uniforme. Los estimulos visuales transformados en visual streams
en el ojo (fotoreceptores, celulas bipolares, ganglionares, etc..) pasan por el chiasma optico
y los nucleos laterales geniculares (LGN, Lateral Geniculate Nucleus) hasta llegar al Visual Cortex donde distintos conjuntos de células estan dedicadas a procesar los
distintos aspectos de los canales que llegan, como orientación, frecuencias espaciales y temporales, dirección del movimiento, etc. Pues de todo esto lo único que
se ha utilizado (modelado) en metricas de calidad son el procesamiento de las frecuencias espaciales y temporales. Las neuronas del cortex se modelan como un banco
de filtros que muestrean la señal a octavas de frecuencia en una dimensión radial de frecuencias y a intervalos uniformes de orientación [14,15,16]. Otro aspecto
modelado de las neuronas del cortes es su saturación al contraste.
Muchos aspectos del visual cortex no se han modelado para PVQA (Perceptual Video Quality Assessment) y sobre todo el procesamiento posterior.
Aspectos Psicofisicos del HVS
Vision foveal y periferica. La mayoria de los modelos de valoracion de la calidad trabajan con visión foveal y otros pocos tambien incorporan
visión periferica [17,18,19,20]. Algunos modelos re-muestrean la imagen con la densidad de fotoreceptores de la fovea para aproximar mas al HVS y proporcionar una
calibración más robusta del modelo [17,18]
Adaptación a la luz. El control de la luz que entra a la retina se produce por la pupila y por mecanismos de adaptación de las celulas
retinianas que ajustan la ganancia de las neuronas posteriores. El resultado de todo esto es que la retina codifica el contraste del estimulo visual en vez de
codiicar la intensidad absoluta de luz que entra. El fenomeno que mantiene la sensibilidad al contraste del HVS sobre un gran abanico de intensidades luminosas
de fondo se conoce como la ley de Weber "Weber's Law"
Funciones de Sensibilidad al contraste. Modelan la variación de sensibilidad del HVS a distintas frecuencias espaciales y temporales presentes
en los estimulos visuales. Algunos modelos del HVS implementan las CSF como una operación de filtrado, mientras que otros como sumatorios ponderados tras una
descomposición en frecuencias. Las CSF varian con la distancia a la fovea, pero si se utiliza visión foveal, entonces se implementan como funciones paso-banda
invariantes, aunque la mayoria de los sistemas las modelan como paso-bajo. La CSF tambien es sensible a la frecuencia temporal y se ha modelado para calidad de video
como simples filtros temporales [21,22,23,24]
Enmascaramiento y Facilitación. La mascara en general reduce la visibilidad de la funcion de referencia en comparación cuando no esta prestente.
Normalmente el efecto es mayor si el contenido en frecuencia y orientación de mascara y referencia son similares. La mayoria de los modelos incorporan enmascaramiento
y solo algunos facilitación [1,18,25]
Pooling. Llegar a una única medida de calidad a partir del conjunto de infomación procesada por los canales visuales (visual streams). No se
conoce todavia como el HVS realiza esta tarea, pues requiere de capacidad cognitiva. La mayoria de las metricas utilizan "Minkoswski pooling" para reunir y
procesar las medidas de error de diferentes canales con distintas frecuencias, orientaciones, coordenadas espaciales etc.. y llegar a una medida de fidelidad.
Como sumario, una MVC debería incorporar los siguientes aspectos
- Optica del ojo. Modelada por una PSF (Point Spread Function) paso-bajo.
- Procesamiento del color
- Muestreado retiniano no uniforme
- Adaptación a la luz (Luminance masking)
- Funciones de sensibilidad al contraste (CSF)
- Analisis selectivo de frecuencias espaciales, temporales y de orientaciones
- Enmascaramiento y Facilitación
- Respuesta a la saturación de contraste
- Pooling
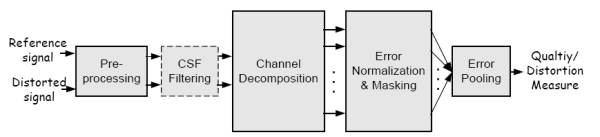
Framework General de metricas basadas en sensibilidad de error.
La mayoria de las MVC comparten el paradigma de "sensibilidad a errores" (Error Sensitivity based paradigm), cuyo objetivo es cuantificar la fuerza de los
errores entre la señal de referencia y la señal distorsionada desde un punto de vista perceptual. Con el framework de la figura se pueden explicar la mayoria de ellas
aunque varien en puntos específicos.
Preprocesado.Alineamiento de referencia y distorsionada, transformación del espacio de color, calibración de dispositivos (paso a unidades de luminancia),
filtrado PSF (low-pass filter simulando la PSF de la optica del ojo) y adaptación a la luz (light adatptation, paso a estimulos de contraste). No hay una definición
universal de contraste para escenas naturales [26]. Los calculos de contraste pueden realizarse durante o tras la descomposición en canales.
Filtrado CSF CSF puede ser simulado antes de la descomposición en canales con filtros que aproximen la respuesta en frecuencia de CSF. Algunas
MVC lo implementan como factores de ponderación tras la descomposición en canales
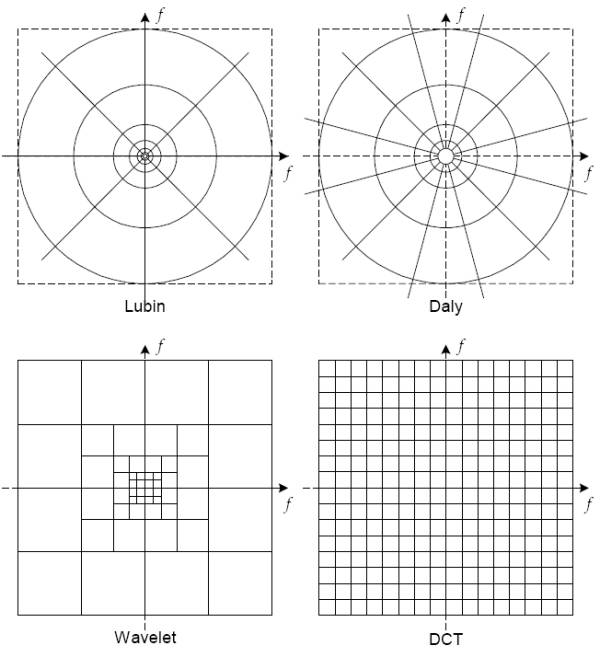
Descomposición en Canales Los canales sirven para separar los estimulos visuales en diferentes subbandas espaciales y temporales. Aunque algunos
modelos utilizan una descomposición sofisticada, las transformaciones simples como la DCT (Discrete Cosine Transform) o la trasformada wavelet son muy utilizadas por
simplicidad aunque no se ajusten bien al modelo cortical neuronal del HVS
 .
.
La transformada de cortex de Watson [27] modela los canales selectivos de frecuencia y orientación de forma similar que funciones Gabor 2D pero más "implementables".
Otras implementaciones [1,17,18,25,28,29,30] intentan aproximarse al HVS manteniendo la simplicidad de la implementación. También se hay descomposiciones en canales para
multiples frecuencias [5,22,23,32].
Normalización de errores y enmascaramiento Normalmente se implementan para cada canal. La mayoria de los modelos implementan el enmascaramiento como
un mecanismo de control de ganancia que determina la señal de error del canal mediante un umbral de visibilidad variable en el espacio (con la posición) [33]. Explica
como se implementa el enmascaramiento y como se utiliza la elevación de umbral (threshold elevation) para normalizar el error. Esta normalización se mide en unidades de
Just Noticeable Difference (JND) donde 1.0 indica que la distorsion en un canal está en el umbral de la visibilidad. Otros métodos implementan el enmascaramiento como
la respuesta a la saturación de contraste basandose en unas curvas de saturación que representan las del HVS.
Error Pooling Es el mecanismo de combinar las diferentes señales de error de los distintos canales en una interpretación única de calidad/distorsión.
La mayoria de los métodos utilizan la formula de Minkowski que se muestra. Se puede procesar la formula sobre espacio y luego sobre frecuencia o viceversa e introducir
no-linelidades. Alguns autores utilizan un mapa de "importancia espacial" de diferentes regiones para proporcionar variabilidad espacial en la ponderación [31,34,35].
Algoritmos de Valoracion de Calidad de Imagenes
Hace una revisión de los principale algortimos de valoración de calidad para imágenes. Para una revisió más profunda nos refiere a [2,36]. No voy a entrar aqui de momento
porque el objetivo es Valoración de Calidad de Video, aunque seguramente tenga que revisar alguno para recurrir a la explicación sobre fundamentos cuando se requiera.
Algoritmos de Valoracion de Calidad de Video
Una manera obvia de aplicar MVC al video es utilizar las técnicas para imágenes cuadro por cuadro (frame-by-frame). Sin embargo, una aproximación mas seria debería tener
en cuenta aspectos temporales del HVS en el diseño de la métrica. Numerosas referencias sobre la extensión de las caracteristicas vistas del HVS a las dimensiones tiempo y
movimiento [5,22,24,32,52,53,54]. Una revisión de distorsiones producidas por la codificación de video en [55]. Una revisión de modelado de MVC para video en [56], (este paper complementa el [56] con otras referencias mas modernas.)
En [53] Tan et al implementan un Video Distorsion Meter usando una MVC de imagen seguida de un "emulador cognitivo" que modela algunos efectos temporales como "smoothing",
enmascaramiento temporal, saturación y seguimiento asimetrico (fenomeno por el que se percibe antes pasos de calidades buenas-malas que malas-buenas).
En [21,22,23,32] se extiende a la dimensión temporal el modelado CSF y generando dos flujos visuales ajustados a aspectos temporales de los estimulos de cada uno de los
canales espaciales. Estos flujos modela los mecanismos de "transición y mantenimiento" temporal del HVS. Proponen una Moving Picture Quality Metric mediante una descomposicion
en escalas orientaciones y flujos temporales. El enmascaramiento lo realiza mediante normalización de los canales de error con estimulos dependientes de umbrales de visibilidad.
Winkler presenta una MVC para video en color [5]. Aplica una transformación de color y aplica la metrica a cada canal. Utiliza [33] para el enmascaramiento.
DVQ (Digital Video Quality) de Watson opera en el dominio de la DCT por lo que es atractiva desde un punto de vista de implementación [24,57].
Tan y Ghanbari [54] tienen como objetivo modelar la calidad de video MPEG combinando con un modelo de sensibilidad de errores y un modelo de medida de "blockiness".
Yu et al. [58] proponen una MVC de video basada en una extensión de Winkler [5] con una metrica de percepción de "blockiness"
Aspectos a considerar antes de desarrollar una MVC:
- Complejidad Computacional. Las metricas mas complejas modelan mejor el HVS, pero a costa de mucha complejidad y/o coste computacional.
- Requerimientos de Memoria. Para implementar filtros temporales hay que almacenar una cierta cantidad de frames para su procesado.
- Dependencia de las condiciones de visualización. Resolución del display, no-linealidades entre pixels y valores de luminancia, distancia del
observador, etc. La mayoria de las metricas fijan o asumen las condiciones.
Limitaciones del Error Sensitivity Framework
El objetivo de este framework es predecir la calidad perceptual mediante la cuantificación de los errores perceptibles, mediante una simulación de los componentes
funcionales del HVS relacionados con la percepción de calidad. Pero el HVS es extremadamente complejo.
La mayoria de los modelos de este framework hacen una serie de asunciones que enumera en el paper, y argumenta que en función de la aplicación del modelo estas
asunciones pueden ser validas o razonables desde el punto de vista practico, pero que la mayoria de las asunciones son discutibles y deberían ser validadas.
Creen que existen numerosos problemas criticos para justificar la utilidad de este framework. Enumeran y argumentan los problemas por los que consideran esto.
- The Suprathreshold Problem. Cuestiona que tras la normalización y el enmascaramiento, la relación entre la magnitud del error y la distorsion
percibida por el HVS pueda ser correctamente modelada para los casos en los que el error en un canal visual es mayor que el umbral de visibilidad. También cuestiona
la utilización de un umbral de "just noticeable visual error" para normalizar los errores para los distintos canales.
- The Natural Image Compexity Problem. La mayoria de los experimentos psicofisicos se realizan con patrones relativamente simples, como rejillas
sinusoidales, cuadros de Gabor, formas geometricas, etc.. Por ejemplo, las CSF son obtenidas de experimentos que utilizan patrones simples de frecuencia. Los experimentos
de enmascaramiento normalmente incorporan dos o unos pocos patrones diferentes. Todo esto es muchisimo mas simple que la complejidad de las imagenes naturales.
-
The Minkoswski Error Pooling Error.La formula de sumatorio de errores de Minkowski esta basada en las diferencias entre
dos señales, pero esto no refleja las diferencias o cambios estructurales de estas señales.
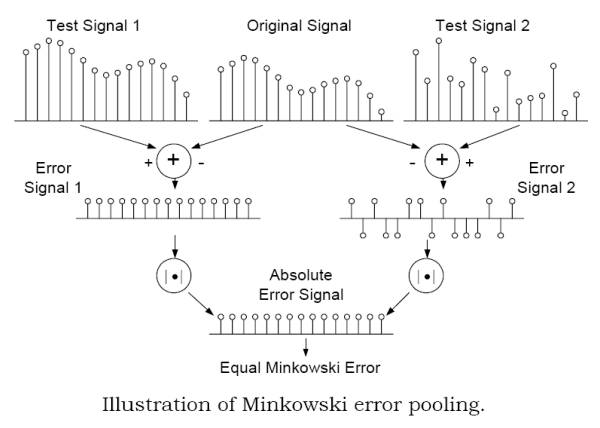
Con el ejemplo de la imagen (explicado en el paper) se ve que no solo es importante la
preservación estructural de la señal sino que el test de Minkowski es ineficiente capturando la estructura de los errores y por tanto las metricas que la utilicen
son metricas con perdida de información estructural "Structural Information Lossy Metrics". Aunque la metrica aplique una descomposición en frecuencia,
si esta descomposición en frecuencia no es capaz de decorrelar la estructura de la imagen la metrica adolecera del problema. Es el caso de las descomposiciones
lineales como la wavelet. Se ha demostrado [60,61] que existe una fuerte correlación entre los coeficientes wavelet
intra- e inter- canal de imagenes naturales. De hecho sin explotar esta fuerte dependencia el estado del arte en la compresión de imagenes mediante
wavelets [62,63,64] no tendrá exito.
- The cognitive Interaction Problem. El conocimiento cognitivo y el proceso visual activo (cambio de fijación) son importantes para el PVQA. Si el
observador está instruido o no en las actividades [2,65], el conocimiento previo de la imagen, la atención y la fijación
[2,66] resultara en una u otra calidad. Hay experimentos en los que la calidad simplemente se puntua diferene por la
inclusión o no de sonidos del conferenciante o de fondo. Actualmente las metricas no tienen en cuenta estos procesos.
Full-Reference Quality Assessment Using Structural Distortion Measures
El Error-Sensitivity Framework considera cualquier distorsión en la imagen como un cierto tipo de error. Puesto que las estructuras de cada error puede tener un
efecto distinto en la percepción de la imagen, la efectividad de este framwork dependera de como se entiendan y presenten las estructuras de estos errores.
La descomposición en canales es la forma mas simple de descomponer las señales de error en un conjunto elemental de componentes cuyos modelos son obtenidos de
experimentos psicofísicos. Por todo lo argumentado hasta ahora este framework se sustenta en un complejo modelo de enmascaramiento y el conocimiento actual sobre los
efectos del enmascaramiento visual es todavía limitado.
Proponen una nueva forma de pensar en relación a la valoración de la calidad de las imagenes: No es necesario considerar las diferencias entre la referencia y la
procesada como ciertos tipos de error. La medida de la distorsión estructural de la imagen puede generar metodos PVQA más efectivos.
En [8,68] se propone esta nueva filosofía. La principal función del sistema visual humano es extraer información
estructural del campo visual, y está muy adapatado para este proposito. Por tanto, una medida de la distorsión estructural puede ser una buena aproximación a la
distorsión percibida de la imagen.
Comparan esta filosofía con la basada en la sensibilidad de errores.
En primer lugar el cambio de concepto, de medida de error a medida de la distorsión estructural. Aunque en muchos casos el error y la distorsión
estructural pueden coincidir, en muchas circunstancias la misma cantidad de error puede deberse a diferencias significativas de distorsión estructural. Ponen como ejemplo una serie de imagenes alteradas con una variedad de distorsiones de forma que presenten aproximadamente el mismo valor MSE respecto al original.
Es interesante ver como imagenes con la misma medida de error tienen grandes diferencias perceptuales de calidad. Sus pruebas subjetivas resultaron en que las distorsiones
contrast stretch y mean shift proporcionan una calidad perceptual alta, mientras que las distrosiones blur y JPEG Compression tienen los valores de calidad perceptual
mas bajos [7,68].
En segundo lugar, otra diferencia importante es que se considera la degradación de la imagen como pérdida percibida de información estructural. La imagen
con mayor contraste tiene mejor indice que la comprimida simplemente porque la primera conserva toda la información estructural de la imagen original. Consideran una
prediccion de calidad la medida de perdida de información estructural porque asumen que el HVS funciona igual, que se ha adaptado a extraer información estructural y
detectar cambios en ella.
Y en tercer lugar, se usa una aproximación top-down que comienza con un nivel alto (intentando simular la funcionalidad hipotetica del HVS), mientras que la filosofía
de sensibilidad a errores utiliza una aproximación bottom-up que intenta simular la función de cada uno de los componentes del HVS y combinarlos con la esperanza
que el comportamiento sea similar al conjunto del HVS.
Como aplicar esta nueva filosofia es un tema abierto, dependera de como se interpreten y cuantifiquen los conceptos de "structural information" y "structural distortion".
En lineas generales habría dos lineas.
Desarrollar un framework que describa las caracteristicas de las imagenes naturales y que la información estructural pueda compararse con la original.
Desarrollar un método de comparación de información estructural.
Una primera implementación en [7,68]
Image Quality Indexing Approach
Proponen un método basado en un indexador de distorsión, el cual se compone de tres factores, perdida de correlación, distorsión media y distorsión de contraste. Estos tres factores son los tres componentes de la ecuación (ver articulo para un desarrollo y explicación).
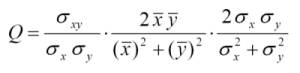
El primer factor es el coeficiente de correlación entre la imagen original y la distorsionada (x e y), que mide el grado de correlación lineal entre ellas y cuyo rango
dinámico es [-1,1]. El mejor valor, 1, es obtenido cuando la correlación cumple la ecuación de la recta, siendo a y b constantes y a>0. Por tanto una transformación lineal
de la imagen mantiene la información estructural, y un valor decreciente de este índice indica cuan no lineal es la transformación que se le aplica a la imagen. Aunque
la original y la distorsionada esten correlacionadas linealmente pueden tener otras distorsiones. De esto se ocupan los otros dos factores del producto.
El segundo factor tiene un rango de [0,1] y mide cuan similares son los valores medios de ambas imágenes. El valor 1 se obtiene si y solo si las medias son iguales.
El tercer factor mide cuan similares son los contrastes de ambas imágenes, con un rango de [0,1] alcanzando el 1 solo si los contrastes son iguales.
Las imagenes no son invariantes espacialmente, por lo que lo deseable es extraer estos estadísticos localmente y combinarlos. Ellos utilizan una ventana deslizante
de tamaño BxB para ir calculando los estadísticos por la imagen desplazando la ventada de izquierda-derecha y arriba-abajo. La siguiente formula realiza la ponderación
de los M pasos siendo Q_j el valor de cada aplicación de la ventana.
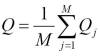
Pasa a analizar los resultados de aplicar este indice a imágenes de referencia con una ventana de B=8, obteniendo buenisimos resultados y segun sus tests subjetivos
totalmente correlacionados con los valores de estos.
Nos redirigen a [69] para ver más imagenes de muestra y para obtener una implementación en Matlab de este indice de indexación propuesto.
El índice propuesto (Q) es una implementacion rudimentaria de la nueva filosofía que aunque pronostica buenos resultados sobre los tests realizados se debe seguir
investigando para enlazar con más elmentos del HVS, proponer mejores indices y optimizar el algoritmo.
Otro importante tema para explorar (a la fecha) es cómo aplicar este indice al video (PVQA). En [70] se ha calculado el índice frame a frame para una secuencia de video
y combinado con otras metricas de distorsión de imagenes como "bloking" para producir una metrica de calidad de video.
Valoración de la calidad con métodos No-Reference y Reduced-Reference
Las métricas presentadas hasta ahora necesitan la imagen original completa para actuar de referencia en la comparación con la distorsionada, lo que es un requerimiento
dificil para el video pues en muchas aplicaciónes el volumen de información a enviar es limitado.
Reduced Reference (RR) Quality Assessment. No asume la disponibilidad completa de la señal de referencia, solo de información de referencia disponible
a traves de canales de datos auxiliares. La figura muestra como un esquema de RR.
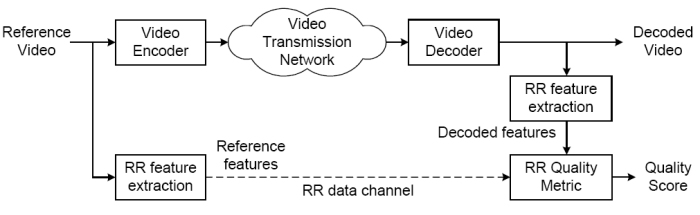
El diseño de metricas de calidad RR tiene que analizar cuál es la información relevante
a transmitir por el canal RR.
Webster et al. propusieron la primera metrica RR en [71] basadas en la extracción de característics de actividad espacial
y temporal. Se utilizan metricas para cada una de estas características (espacio-temporales). Estas características son transmitidas por el canal RR. Las metricas
usadas son entrenadas con datos obtenidos de observadores humanos. El tamaño del canal RR depende del tamaño de las características extraidas.
Este trabajos se ha extendido en [72] usando filtros de mejora de bordes y extrayendo dos caracteristicas en una ventada 3D.
Definen una metrica de alteraciones y reportan también resultados subjetivos.
Otra aproximación en [73] utiliza marcadores de bits ocultos en los frames enviados en el canal principal. También son enviados por el canal RR y una medida de la
diferencia entre ambos se establece como indicador de perdida de calidad.
En [74] se utiliza la incrustación de una marca de agua "watermarking" en la imagen original y se sugiere que una perdida de calidad en la marca de agua indica una
degradación medible en la calidad global del video.
Siendo estrictos los dos métodos anteriores no son realmente RR, pues no extraen información de la imagen, sino que añaden referencias cuya distorión medible en el destino
lo interpretan como medida de calidad.
No Reference (NR) Quality Assessment. Debido el éxito relativo de los métodos FR no sorprenderá que el diseño de métodos NR sea muy dificil. Esto es
debido en parte al conocimiento limitado del HVS y los aspectos cognitivos del cerebro humano. Sólo se han propuesto unos cuantos métodos para NR-QA (No Reference
Quality Assessment) [75,76,77,78,79,80]
VQEG considera que la estandarización de NR-PVQA y RR-PVQA son direcciones de trabajo futuras donde la distorsión mas considerada es la "DCT-block based compression".
El problema de NR es que existen muchos factores no cuantificables que juegan un papel importante en la valoración subjetiva de calidad, como son estética, relevancia
cognitiva, conocimiento, aprendizaje, contexto visual, etc. Además estos factores son variables entre individuos. Sin embargo se puede trabajar con NR con la siguiente
filosofía: Todas las imágenes y videos son perfectos a menos que se distorsionen durante su adquisición, procesado o reproducción. Por tanto la tarea de NR
se limita a medir las distorsiones posibles introducidas en estas etapas. La referencia entonces, en un NR, son las estadísticas de imágenes naturales (y videos)
medidas respecto a un modelo que mejor se ajuste a un tipo de distorsión o aplicación.
De esta forma todas las imágenes "perfectas" son tratadas por igual independientemente de valor estético [82,83]. En
estas métricas se asume que las distorsiones de las imágenes son aquellas cuyas estadísticas se separan sustancialmente de las estadísticas de las "perfectas imágenes
naturales". Por ejemplo, las imágenes naturales no contienen "bloking artifacts" y la presencia de una discontinuidad en bordes en las direcciones vertical y horizontal
con un periodo de 8 pixels probablemente se deben a una distorsión introducida por una compresión block-DCT. Algunos aspectos del HVS como texturas y enmascaramiento
de luminancia también se modelan. Por tanto las métricas NR no sólo tienen que modelar el HVS sino las estadísticas de las imágenes naturales.
En [82] se usa un modelo estadístico de las imagenes naturales en el dominio wavelet usado para valoración de
calidad de imágenes JPEG2000.
Cierto tipo de distorsiones como los "blocking artifacts" son fáciles para las NR. Otras no. La transformada wavelet se aplica a la imagen completa y no produce,
por ejemplo, "blocking". Por tanto las metricas NR que se basen en "blocking artifacts" fallaran si el procesdo de la imagen distorsionada es uno u otro. Por tanto
cada metrica NR deberá disañarse especificamente para un determinado tipo de imágenes objetivo.
Cuanto más sofisticado sea el modelo de las imagenes naturales mejor rendimiento tendrán las métricas NR siendo mas robustas a distintos tipos de distorsiones.
Validación de la Calidad Subjetiva
En este apartado hace una revisión de los métodos de valoración subjetiva de la calidad, como el Single Stimulus Continuous Quality Evaluation y el
Double Stimulus Continuous Quality Scale. Ver paper.
Comparación de métricas de valoración de calidad
No se ha publicado mucho acerca de la comparación de estos modelos bajo condiciones experimentales extrictas y sobre una gran variedad de distorsiones, fuerza de estas,
contenidos de estimulos y criterios de valoración subjetiva. Esto es debido a que validar los algoritmos es caro en tiempo y costo, estando la mayoría de los métodos,
además, escasamente documentados en la literatura para poder ser reproducidos con el objetivo de medir su rendimiento y compararlos. La mayoría de las métricas no son lo
suficientemente genericas como para inferir
En [3,65] se hace una compartiva de medidas que no operan por descomposicion en canales y su rendimiento se tabula para varias condiciones de test.
En [85] Lie et al. comparan los modelos de Daly y de Lubin y concluyen que el de Lubin es mas robusto que el de Daly para sus procedimientos.
En [86] se comparan tres métricas para compresiones JPEG, la de Watson DCT [87], la de Chou y Li [50] y la de Karanusekera Y Kingsbury [49]. Concluyen que la
de Watson es la de mejor rendimiento de las tres.
Martens y Meesters han comparado la metrica de Lubin (también llamada Modelo de Sarnoff) con el RMSE [9] en imagenes
con transformaciones de luminancia. Las metricas se compararon utilizando experimentos subjetivos basados en imagenes corrompidas con ruido y "blur" y con
compresión JPEG. Concluyeron que "En ninguo de los casos examinados se puede demostrar una clara ventaja de metricas complicadas (Sarnoff) y metricas simples como RMSE"
[9]
Video Quality Expert Group
Comentan sobre VQEG y su origen y objetivos. Ver paper.
Conclusiones y direcciones futuras
Respecto la aproximación de sensibilidad a errores, uno de los aspectos más importantes y que requiere de mas investigación
es varios efectos de enmascaramiento/facilitación sobre todo en el rango por encima del umbral de visibilidad (suprathreshold
range) en lso casos en los que la imagen de fondo sea una imagen natural, en vez de con patrones simples [88,89]. En [90] se
hace un estudio de patrones de contraste incluyendo imagenes naturales. Comparando estos modelos (error-sensitivity) con estos
patrones se puede llegar a una mejor comprension del HVS.
En cuanto al "Structural Distortion Framework" esta en una fase prelimiar (a la fecha). El Quality Index es atractivo no
solo por sus resultados si no por su simplicidad. Sin embargo puede ser muy simple y un estudio teorico mas profundo de como
estan interconectadas la imagenes naturales y la percepción visual pueda ayudar. Tambien se le puede dotar de un analisis
multiescala, ventanas adaptativas y un pooling espacial invariant usando un modelo estadístico fijo. Cuaquier otro enfoque
bajo el mismo Framework puede ser posible, simplemente redefiniendo el concepto "Structural Information".
Otra linea intersante es combinar los dos frameworks, "error-sensibility" y "structural distortion". Una aproximación
podría ser utilizar el método de "structural distortion" para medir la cantidad de información estructural perdida y el
"error-sensibility" para ayudar a determinar si dicha perdida puede ser percibida por el HVS.
Los campos de NR y RR son muy jovenes y hay muchas posibilidades de desarrollo de metricas novedosas. El exito de los modelos
estadísticos de las escenas naturales derivaran en el exito de las metricas NR y RR. Una combinación de modelos de escenas naturales
con modelso del HVS también puede proporcionar beneficios a NR y RR.