[Winkler_1999b]
A Perceptual Distortion Metric for Digital Color Video
Resumen:
Abstract: Presenta una métrica de distorsión para secuencias de video en color, basada en un modelo de control de ganancia del HVS que incorpora aspectos espaciales, temporales y de percepción de color. Se ajusta bien a los datos de experimentos psicofísicos para la sensibilidad al contraste y enmascaramiento, tanto en luminancia como en estimulos en color. Se ha usado la métrica para valorar la calidad de secuencias codificadas con MPEG.
Se encuentran recientemente QAMs (Quality Assessment Metrics) basadas bien en la explotación de el "conocimiento a priori" de las imperfecciones que introducen los métodos de compresión y las que se basan en modelos del HVS, que son mas generales. Aqui presenta una del segundo tipo, por lo que es independiente del método de compresión utilizado. Está basada en la de [17] (VanDenBrandenLambrecht) y el modelo de visión (del HVS) está basado en otro del autor para imágenes fijas [30] que se enfoca en los aspectos:
- Percepción del color (teoria de los colores opuestos)
- Mecanismos espaciales y temporales
- Sensibilidad al contraste espacio-temporal y enmascaramiento
- Propiedades de las respuestas neuronales del Visual Primary Cortex (V1)
El modelo de visión
Esquema
La estructura del modelo del HVS se muestra en la figura.
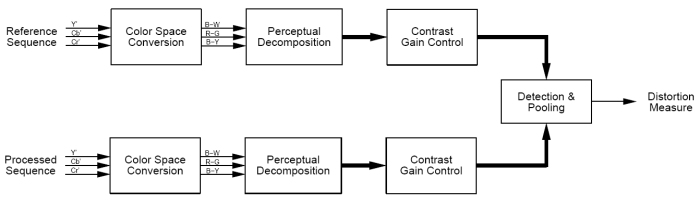
Tras la conversión de la entrada al espacio de color de los colores opuestos, cada una de las componentes de color se descompone espacio-temporalmente genrando un numero de canales perceptuales. Se ponderan los canales de forma que pasen una etapa de control de ganancia para que se ajusten a los umbrales empiricos de sensibilidad al contraste obtenidos por otros autores [15,16]. Las secuencias referencia y procesada, tras pasar por las mismas etapas, se combinan en un sensor de diferencias para dar la medida de distorsión.
Conversión del espacio de color
Realiza una conversión del espacio de color Y'Cb'Cr' definido en la ITU-R Recommendation 601 [13] a un espacio de colores opuestos basandose en el modelo de [20,21]. Primero pasa a R'G'B' (RGB de 0 a 1) tal como dice la ITU (ver paper). Luego pasa los componentes por una función no lineal para adaptarlo a la salida o comportamiento convencional de un display CRT. Luego, conociendo la sensibilidad de los conos del HVS por [24] y basandose en el modelo de [20,21] obtiene los valores de los canales de color opuesto B-W (Black-White), R-G (Red-Green) y B-Y (Blue-Yelow) con la matriz propuesta.
Descomposición perceptual
Primero realiza una descomposición temporal y luego espacial. Comenta que aunque esta separación no está exenta de problemas los dos dominios (temporal-espacial) pueden ser consolidados en un proceso de ajuste explicado posteriormente.
Mecanismos temporales
Los filtros temporales utlizados se basan en los trabajos de Fredericksen y Hess [5,6] que los modelan mediante derivadas de la función de respuesta de impulso que muestra en el paper y que como muestra en las graficas se ajustan muy bien al modelo de los mecanismos sustained y transient. Explica como se han implementado estos filtros (sustained y transient) con IIR. Comenta que el filtro paso-bajo se ha aplicado a los tres canales de color (B-W, R-G, B-y) pero el filtro paso-banda (transient para altas frecuencias) solo se ha aplicado a la luminancia (B-W) porque se basa en que la sensibilidad al contraste del color a altas frecuencias es mucho menor en el HVS que para bajas frecuencias.
Mecanismos espaciales
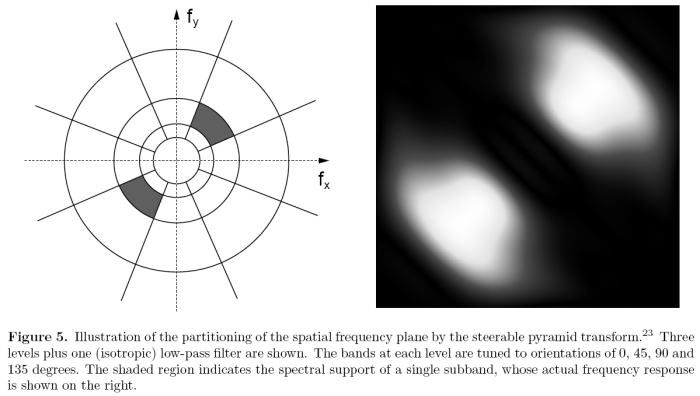
La descomposición del dominio espacial la hace en base de la "steerable pyramid transform" de Simoncelli et al. [23] cuyo código y filtro está disponible aqui. Esta transformación descompone la imagen en un número de bandas de frecuencia y orientación que para un uso en un modelo de visión tiene la ventaja que es invariante a la rotación, auto-invertible (que no entiendo que es eso) y que minimiza el aliasin entre las subbandas. En la implementación que se hace en este articulo los filtros base tienen un ancho de banda y espaciado de octavas, cinco niveles de subbandas con cuatro orientaciones mas una central de paso-bajo isotropica. La misma descomposición se usa para todos los canales. En la imagen se observa el particionamiento del plano de frecuencias espaciales.
Sensibilidad al contraste
Tras la descomposición temporal y espacial, cada canal es ponderado de tal forma que la suma de todos se aproxime a la sensibilidad espacio-temporal del HVS. (Como hace esto no me queda claro, si es en una etapa no mostrada en el esquema o dentro de la fase de control de ganancia). Comenta que aunque esta aproximación es menos exacta que aplicar un pre-filtrado a los canales B-W, R-G y B-Y con sus respectivas funciones de sensibilidad al contraste, es mas simple de implementar y ahorra tiempo de computación. Desde un punto de vista práctico esta aproximación es aceptable como muestra en resultados.
Etapa de control de ganancia de contraste
El modelado de la sensibilidad a patrones es uno de los componentes de la valoración de calidad de video mas críticos porque la visibilidad de las distorsiones es altamente dependiente del fondo local. Este fenómeno también es conocido por masking. Para investigar este fenómeno se hacen experimentos donde un estímulo simple (el target), como una sinusoidal o un Gabor patch se sobreimpone a un estimulo de fondo (el "enmascarador" the masker). Con algunas excepciones, el target se hace mas dificil de detectar que el masker conforme aumenta el contraste de este último. En el contexto de compresión digital de vídeo, el ruido de codificación (el producido por la propia codificación o compresión) hace de target y la imagen original de masker.
El enmascaramiento es mas fuerte dentro del mismo canal perceptual (la mayoria de los modelos se limitan a éste) pero experimentos psicofísicos demuestran que también ocurre en canales de distinta orientación o en canales de distinta frecuencia espacial o entre canales de distinta crominancia. Estos modelos se inspiran en los análisis de la respuesta de las "simple cells" en el visual cortex del gato, donde el control de ganancia sirve como mecanismo para mantener la respuesta neural dentrod e un rango dinámico admisible mientras que al mismo tiempo retiene información global de patrón.
Explica como ha utlizado una generalización del modelo de excitación-inhibición de Watson y Solomon [29] para el color (bastante complejo).
Detección y Pooling
Se sabe que todo el proceso anterior tiene lugar en el V1 o Visual Cortex, y que a partir de ahi, a partir de la V2, la informacíon presente en los distintos canales es integrada. Este proceso (cognitivo) puede ser simulado reuniendo la información de los canales en base a reglas de probabilidad o sumatorio de vectores, lo que se conoce como pooling.
La etapa de pooling combina las diferencias entre, la salida de los sensores (aplicación de la fase de control de ganancia a los canales) para la señal de referencia y la señal procesada (codificada o comprimida) para distintas dimensiones. Muestra el sumatorio (teorico).
Tal como comenta, en principo cualquier dimensión puede ser utiliada para el sumatorio mostrado, dependiendo de el tipo de resultado que se desee obtener. (Esto no termino de verlo). Por ejemplo, pooling sobre diferencia de localización de pixels puede omitirse para hacer un mapa de distorsión para cada frame de la secuencia (No dice como, me resulta oscuro).
Resultados
Ajuste del modelo
El modelo contiene varios parámetros que deben ajustarse para que el resultado se ajuste al HVS. Ha usaso el umbral de sensibilidad al contraste y enmascaramiento de experimentos. En el proceso de ajuste de parametros la entrada de la métrica imita el estímulo usado en estos experimentos y los parámetros han sido ajsutados de tal forma que la salida se aproxime a las curvas de umbral de éstos.
La sensibilidad al contraste ha sido modelada estableciendo la ganancia de los filtros temporales y espacieles de tal forma que el modelo se ajuste al umbral empirico de los experimentos de sensibilidad al contraste espacio-temporal, tanto para color como para luminancia. Explica a que valores y porqué se han establecido los parametros de la fase de controld de ganancia.
Para el pooling se ha usado la formula presentada en esa sección y con un beta=2 para canales y pixels (no entiendo muy bien esto) y con un beta=4 para el pooling sobre frames. Estos valores explica porqué han sido seleccionados.
Los resultados muestran que el modelo con los parametros mencionados ajusta bien a las diferencias observadas por distintos observadores. Que la mayoría de los efectos encontrados en experimentos psicofísicos son capturados por el modelo.
El modelo tiene dos pegas fundamentales. Debido a la naturaleza no lineal del modelo los parametros solo se pueden aproximar por un método iterativo de minimos cuadrados, lo que requiere gran tiempo de computación. Además no es flexible, una vez fijados unos buenos parámetros solo son válidos para un determinado "viewing setup" (no se como traducir eso). Comenta que falta trabajo para eliminar estas limitaciones.
Demostración
Ver paper.
Bibliografía disponible:
[23]
[Simoncelli_Freeman_Adelson
_Heeger_1992]Shiftable multi-scale transforms
[30]
[Winkler_1998]
A perceptual distortion metric for digital color images
[29]
[Watson_Solomon_1997]
Model of visual contrast gain control and pattern masking