[Watson_Hu_McGowan_2001]
DVQ: A digital video quality metric based on human vision
Resumen:
El resumen de este artículo incluye el resumen del articulo Watson_1998 (por lo que los enlaces de éste apuntarán al actual), ya que la metrica que se expone aqui es la misma que en dicho articulo pero resumida (aqui se extenderá la explicación basandose en el original), ya que la aportación del presente respecto al anterior son los apartados Testing the Metric, DVQ Predictions y Comparing Data and Metric.
En este articulo se presenta una extensión de las métricas de imagen [2,3,4,5](algunas disponibles en Watson) que incorporan modelos simplificados del HVS al dominio del tiempo y midiendo los resultados de la métrica propuesta en [1]. Tanto las métricas referenciadas como ésta están basadas en la Discrete Cosine Transform, porque reduce la carga computacional que las VQAM (Video Quality Assessment Metrics) propuestas anteriormente [7,8,9,10,11,12] reducen su campo de aplicación. El objetivo de la actual es procporcionar una métrcia que sea razonablemente ajustada (a la valoración subjetiva) y computacionalmente eficiente.
Priemero presentan un informe de la visibilidad del ruido dinámico producido por la cuantización DCT, dynamic DCT quantization noise. Se ajustan a los datos con un modelo matemático que formará parte de la métrica. Luego describe el proceso paso a paso de la métrica (insuficiente para reproducir fácilmente). Por último compara la métrica con datos publicados de experimentos psicofísicos y describe la aplicación de la métrica a una secuencia de video de ejemplo.
Visibilidad del Dynamic DCT Quantization Noise
La métrica DVQ calcula la visibilidad de los artefactos producidos en el dominio DCT. Han generado un nuevo estímulo llamado Dynami DCT Noise para el cual han medido los umbrales visuales humanos. El estímulo es un cuadrado formado por bloques de pixels 8x8 de tal forma que en cada uno se aplica una DCT de la misma frecuencia pero la fase aleatoriamente entre 0 y 2Pi. Generan una secuencia de frames con estas características comentando que representa el error de quantización esperado por los coeficientes DCT, aunque a una estrecha banda de frecuencia. Para una secuencia de frames modulan cada función (cada bloque) con una función de Gabor en el tiempo (Gausiana por Sinusoidal) de una determinada frecuencia temporal y fase. La figura muestra un ejemplo de la secuencia del estímulo con una frecuencia {3,3} con 8x8 numero de bloques y un frame rate de 60Hz. (Aunque no entiendo muy bien todo el proceso, lo explica un poco más en el paper, la figura aclara cual es el objetivo).

Presentan el modelo matemático que se ajusta a las curvas de los test subjetivos llevados a cabo, en los que se observa que exite un aumento del umbral a altas frecuencias espaciales y temporales. El modelo es separable y es el producto de una función temporal, una espacial y otra de orientación. Aunque no cubre todo el espectro de frecuencias. Para HDTV deberían extrapolar el modelo.
DVQ
El objetivo de la métrica es conseguir un buen ajuste a los resultados subjetivos manteniendo una gran simplicidad. Por eso, sustituyen la etapa de filtrado espacial que implementa los canales múltiples del HVS y que se propone en otra métricas [7,11,12,15,16] por un proceso de DCT. Argumenta que esto es una ventaja considerable debido a la existencia de hardware especializado en esto y que para la mayoría de las aplicaciónes los coeficientes ya están disponibles del proceso de compresión.
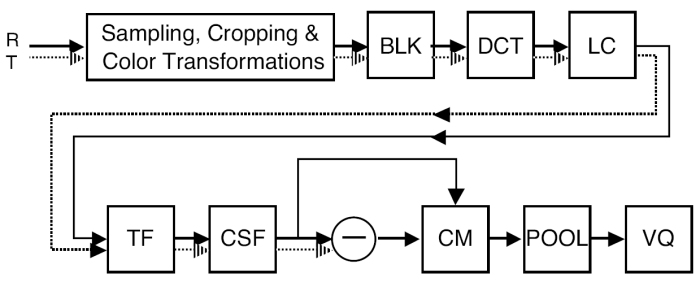
La figura muestra un esquema de los componentes o fases de la métrica. La entrada son dos secuencias de imágenes, la Referenica y la de Test.
El primer paso consiste en varios muestreos, recortes y transformaciones de color que sirven para restringir el proceso a la sregiones de interes y expresar la sencuencia en un espacio de color perceptual. Este paso puede incluir "the registration" de las dos secuencias si es necesario (no explica esto más y no termino de adivinar de que se trata). Tampoco explica lo del recorte como lo hace y en que se basa para establecer las zonas de interés, ni cita referencia alguna donde se describa. Luego realizan un cambio de espacio de color. El espacio de color al que pasan es el YOZ que han usado previamente para el modelado de errores perceptuales en compresión de imágenes estáticas (pero no cita donde). Y es lumninancia en candelas/m2, O es un canal de color opuesto con una determinada matriz de conversión (la muestra), y Z es el canal azul dado por al coordenada CIE Z. Esta transformación normalmente la realizan con una transformación gamma segida de una transformación lineal de color. En este primer paso también realizan un de-interlacing.
A las secuencias se les pasa una transformación DCT por bloques (BLK+DCT) y el resultado se transforma a medidas de contraste local (LC). El contraste local es la relación (ratio) entre la amplitud DCT y la amplitud DC del bloque correspondiente. Lo que hacen es, primero exten los coeficientes DC de todos los bloques. Los filtran usando un filtro paso-bajo de primer orden IIR con una ganancia de 1 y una constante de tiempo. Los coeficientes DCT se dividen bloque a bloque por el coeficiente DC filtrado. Los bloques Y y Z se dividen por los coeficientes DC Y y Z y el bloque O se divide por el coficiente DC Y. En cualquier caso se añade una constante al divisor para evitar la división por cero. Luego los coeficientes los normalizan mediante uan funcion de contraste unitario. Estas operaciones convierten cada coeficiente DCT en un numero entre -1 y 1 que expresa la amplitud de la correspondiente función base como fracción de la luminancia media de el bloque. Los coeficientes DC los procesa analogamente ver Watson_1998 para el detalle.
El siguiente paso es un filtrado temporal (TF) que implementa la parte temporal de la función CSF del HVS que se realiza medieante un filtro recursivo discreto de segundo orden. Ver Watson_1998 para el detalle.
Los resultados se convierten a Just-Noticeable Differences mediante la división de cada coeficiente DCT por su correspondiente umbral visual, lo que implementa la parte espacial de la CSF, (CSF). Estos umbrales salen del modelo matemático que ajustan a los datos de su dynamic DC Quantization Noise en concreto de las ecuaciones 3 y 4. En el paper se indican más detalles de este paso. El uso de jnd's como una medida de visibilidad en metricas de calidad de imagen viene del trabajo de Carlson_1980, y en Sarnoff_1997 se tiene información más detallada del algoritmo de Just Noticeable Differences.
Del paso de Contrast Masking no explica demasiado, mejor leer el paper.
Utiliza un pooling con un sumatorio de Minkowski que muestra. Sumatorio por todas las dimensiones aunque como comenta se pueden realizar sumas anidadas, por ejemplo primero sumar por la dimensión de color y el resultado sumarlo sobre dimensiones de bloque. Comenta, al igual que otros autores que con el sumatoriod e Minkowski se pueden, por tanto, obtener métricas de errores específicos (de canal entiendo) o bien globales.
Para resultados y simulaciones ver paper. Realiza además una comparativa de la metrica con otras.
Bibliografía disponible:
[1]
[Watson_1998]
Toward a Perceptual Video Quality Metric