[Yu_Wu_Winkler_Chen_2002]
Vision Model Based Impairment Metric to Evaluate Blocking Artifacts in Digital Video
Resumen:
Abstract: En el paper presentan métricas VQAM para proponer una simplificación sin comprometrer la precisión. Utilizan un modelo basado en datos subjetivos presentados por el VQEG. La metrica propuesta se llama Perceptual Blocking Distortion Metric (PDBM) y se basa en el hecho de que los blocking artifacts solo se perciben en ciertas regiones de una imagen. Presentan un método para segmentar las regiones donde más se produce el blocking y las distorsiones perceptuales de estas regiones se suman para formar una medida objetiva de blocking artifacts. Han realizado tests tanto objetivos como subjetivos y el rendimiento de la PBDM se valora medieante un número de medidas como el ranking de correlación de Spearman (Spearman rank order correlation), la correlación de Pearson (Pearson correlatio) y el error absoluto medio (Average Absolute Error). Los resultados muestran una fuerte correlación entre los indices objetivos de blocking y el Mean Opinion Scores sobre blocking artifacts.
En la métrica propuesta las regiones blocking dominantes se segmentan mediante el algoritmo propuesto tras una descomposición espacio-temporal basada en un modelo del HVS que tiene en cuenta la arquitectura multicanal, la sensibilidad espacio-temporal al contraste y el emascaramiento de patrones. El modelo utilizado es un refinamiento y simplificación del utilizado en [10,13,14] de forma que se reduzca la carga computacional de la métrica.
Utiliza los bloques habituales en las métricas, una descomposición multicanal para la que utiliza la Steerable Pyramid tras un filtrado temporal, una fase de control de ganancia de contraste, detección y pooling. Los filtros temporales y los filtros que implementan la función CSF siguen el modelo de Branden Lambrecht de su NVFM (Normalization Video Fidelity Metric) [13] que se extiende al PDM (Perceptual Distrotion Metric) de Winkler [14] para varios canales de color. En la PDM se modifica la etapa de control de ganancia de contraste por la de Watson y Solomon [37].
Respecto a la percepción de color, puesto que se muestra en [40] que no se pierde gran precisión al trabajar con un único canal de color (lumniancia) para el modelo de visión, en la métrica se usa solo el canal de lumniancia, con la ventaja de reducir a un tercio la carga computacional. Si la precisión fuera crítica para la aplicación siempre se puede ampliar el modelo a crominacia como en [14].
Aunque normalmente se implementan los dos mecanismos temporales, sustained channel y transient channel, en la métrica se implementa solo el sustained channel como filtro temporal. Esto lo hacen porque la mayoría de las distorsiones aparecidas en experimentos con la PDM aparecen en este canal. Muestran en resultados que es posible conseguir una alta precisión con un único filtro temporal con la ventaja de reducir a la mitad la complejidad computacional.
Existe una gran variedad de descomposciones espaciales en los modelos de visión, Laplacian Pyramid [15], DCT [16], hex-QMF de Teo and Heger y la también suya Steerable Pyramid [36] de las cuales al última es preferida y usada en la métrica por ser invariante a la rotación del estímulo, auto-invertible y minimiza la cantidad de aliasing que se produce intra-subbanda.
En cuanto a la CSF, ya que el filtrado espacial ya decompone las secuencias (referencia y procesada) en distintos niveles de frecuencia, el filtrado CSF se puede implementar [14] mediante el producto de cada subbanda con el adecuado coeficiente CSF, lo que constituye una basta aproximación (pero muy rapida) a la respuesta deseada de la CSF.
Cuando se implementa la Steerable Pyramid, hay que llevar cuidado con los bordes de la imagen cuando se necesitan pixels que caen fuera de la imagen para realizar el filtrado. En el paper se utiliza solo la región central de la imagen dejando mas pixels de los bordes sin usar que en la aproximación de la PDM.
En cuanto a la etapa de control de ganancia de contraste, se realiza tras la descomposición espacio-temporal y el filtrado CSF. En el paper utilizan el modelo de Teo and Heeger de control de ganancia de contraste, que consiste en una fase excitatoria-inhibidora seguida de una fase de normalización. En el paper muestra y explica la formula para hacerlo, e indica que con ella el enmascaramiento se realiza sobre todas las orientaciones simultaneamente para cada subbanda de frecuencia espacial.
La salida de la Steerable Pyramid (descomposción en frecuencia espacial) será la entrada de la fase de control de ganancia, por lo que hay que llevar cuidado de si ésta está dentro del rango dinámico del modelo de control de ganancia de contraste o satura la respuesta. Para los filtros paso-banda la entrada está dentro de este rango. Pero para el filtro paso-bajo no es el caso debido a que la DC Component (Direct Current Component) no se ha separado de los coeficientes antes de la descomposición y esta energía se acumula en la banda paso-bajo. Tras la descomposición los coeficientes de esta subbanda se hacen tan grandes que estan fuera del rango dinámico del modelo de control de ganancia. Por tanto el valor medio (ver DC Component) se resta de cada pixel del frame correspondiente en el dominio espacial antes de la descomposición, para prevenir esta acumulación de energia en esta banda.
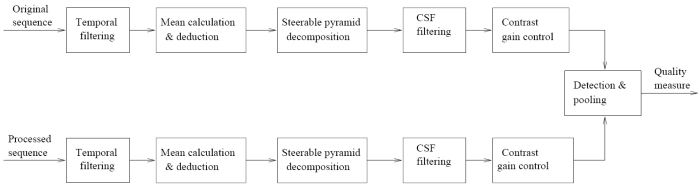
El esquema general de la métrica es el de la imágen. En caso de que las secuencias sean entrelazadas se pasan solo al filtrado temporal los campos impares de la componente de luminanacia. El filtrado temporal diseñado por [13] se implementa como un filtro de primer orden IIR con muy poco retardo y con poco almacenamiento. Tras el filtrado tempoal se calcula el valor medio de cada frame (entiendo de lumninancia) y se resta al valor de cada pixel coefficient. Le sigue la Steerable Pyramid, descomposición en los siguientes seis niveles de frecuencia, un nivel paso bajo, cuatro niveles paso-banda y un nivel paso-alto. El primero y el último isotrópicos. La salida de cada subbanda se multiplica por su coeficiente CSF correspondiente para ajustar la ganancia global de la métrica a la curva de sensibilidad de contraste del HVS. En la etapa de control de ganancia la entrada de cada subbanda se normaliza según la ecuación que muestra en el paper. Las etapas de detección y pooling integran los datos de todas las subbandas, emulando la integración del proceso visual en el cortex, siguiendo la squared error norm que muestra en el paper (diferencia normalizada entre la salida procesada y la original) lo que da una medida de distorsión. El mapa de distorsión perceptual de cada frame se puede generar mediante la suma de bandas de frecuencia y orientación. En el mapa cada pixel representa el valor de distorsión espacial en esa localización.
Relación con otras métricas: Está basada en la NVFM y la PDM, pero las diferencias (listadas en la tabla del paper) sugen porque la métrica no necesita conversión de espacio de color, solo tiene un canal temporal y descarta mayor número de pixels en los bordes de la imagen, por lo que la complejidad computacional es mucho menor. Con una buena parametrización, el rendimiento de la métrica es comparable a las otras métricas. Esta parametrización la hace en base al algoritmo que menciona en el paper y utilizando secuencias de 60Hz subconjunto de las utlizadas por los tests subjetivos del VQEG. La parametrización consiste en encontrar los valores de los coeficientes de sensibilidad al contraste para la CSF y los 4 pares de valores para los parametros de la formulación presentada. En el paper describe como incluso con pseudocódigo.
Además de presentar la metrica anterior, utilizan un segmentador de regiones en base a la cantidad de blocking. Blocking artifacts se definen en [2] como discontinuidades a lo largo de los bordes de los bloques utilizados en los algoritmos de compresión (habitualmente DCT). Para tener una medida precisa de la cantidad perceptual de estas discontinuidades se basan en que diferentes distorsiones se dan en diferentes regiones de las imágenes comprimidas, por ejemplo el ringing se da alrrededor de los bordes de objetos con alto contraste, mientras que el blocking se nota más en regiones uniformes o con poca variación (smooth regions).
Asumen que las distorsiones que contribuyen a una medida perceptual de éstas se dan en regiones dominantes, por lo que para realizar una medida de estas distorsiones es útil segmentar la imagen en dichas regiones para no procesar toda la imagen en el cálculo de esta medida. De la métrica anterior se puede generar un mapa de distorsión perceptual por frame, donde cada pixel tiene el valor de la distorsión perceptual. Esto junto con una segmentación de regiones dominantes de bloking puede utilizarse para calcular una distorsión perceptual acumulativa en estas regiones.
Pesentan la métrica Perceptual Blocking Distortion Metric (PDBM) que integra un nuevo algoritmo (explicado en la siguiente sección del paper) de segmentación de regiones dominantes en bloking. Es la nueva etapa que se observa en la figura. En la etapa de pooling, la suma de las diferencias entre las secuencias original y procesada se calcula sobre la frecuencia espacial y las subbandas de orientación, pero teniendo en cuenta los elementos que entran en cada región del blocking map y luego mediado por el número de farmes (en el paper viene la formulación). Esto da una medida d de distorsión por blocking que debe ser convertida a Objective Blocking Ratin (OBR) que es una escala de cinco grados (1-5) de defectos propuesta por la ITU-R Rec. BT. 500-9 [9]. Presenta la formulación de esta conversión y comenta que el ajuste de los parametros se hace en base a experimentos para ajustar mejor el OBR al MOS (Mean Opinion Score).
Bibliografía disponible:
[10]
[Teo_Heeger_1994]
Perceptual Image Distortion
[14]
Winkler_1999b
A perceptual distortion metric for digital color video
[15]
Sarnoff_1997
Sarnof JND Vision Model Algorithm Description and Testing
[16]
Watson_1998
Toward a Perceptual Video Quality Metric
[36]
Simoncelli_Freeman_Adelson
_Heeger_1992.pdfShiftable Multi-Scale Transforms
[37]
Watson_Solomon_1997
A Model of Visual Contrast Gain Control and Pattern Masking.