[Resumen]
Contenido
- Valoración Objetiva de la Calidad en Imagenes y Video
- Clasificación de los Métodos
- Aproximaciones, Frameworks o Filosofías
- Error Sensitivity Framework (ESF)
- Structural Distortion/Similarity Framework (SDF)
- Statistics of Natural Images Framework (SNI)
- Hybrid Framework. Visual Information Fidelity
- Descripción
- Comparaciones de Métricas
- Video Quality Expert Group
- Lineas de Investigación
- Apendice I - HVS e implicaciones en PVQA
- Optica del Ojo
- Fotoreceptores y Visión Foveal/Periférica
- Percepción del color
- Adaptación a la luz y Sensibilidad al Contraste
- Enmascaramiento Espacial y Temporal / Facilitación
- Mecanismos Espaciales y Temporales del HVS
- Diseño de Filtros. Descomposición en canales
- Adaptación de patrones
- Pooling
- Proceso Cognitivo
Valoración Objetiva de la Calidad en Imagenes y Video
El objetivo de la investigación en la valoración objetiva de la calidad de imagen y video es diseñar métricas de calidad que puedan predecir automáticamente (algoritmicamente) la calidad de imagen o video percibidas, ajustandose lo más posible a las valoraciones subjetivas de los individuos destinatarios de las imagenes o videos.
El resumen comienza con una clasificación de los métodos encontrados de análisis de la calidad de las Imagenes/Video, y una somera descripción de éstos y la justificación de la clasificación y repasamos los frameworks que he identificado por la bibliografia encontrada.
Para poder entender muchas de las características de los frameworks y métodos que se utilizan en la Valoración Objetiva de Calidad de Imágenes/Video es necesario tener unos conocimientos básicos sobre el Sistema Visual Humano (Human Visual System, HVS) o al menos de las características de éste que pueden ser utilizadas por estos sistemas de valoración y cuales son los modelos que las implementan y a grandes rasgos cómo lo hacen. Para ello se hace una presentación en el Apendice I de estas características y cómo (sin entrar en detalles) se han implementado por los distintos autores. La mayoría de estas características se explican dentro del contexto de uno de los frameworks (el Error Sensitivity Framework), pero es importante tenerlas en cuenta y ver como se han resuelto en este entorno para extrapolarlas al resto.
Clasificación de los Metodos
Los algoritmos de valoración de la calidad de imagen o video se pueden clasificar de diversas formas, la mayoría de los reviews siguen más o menos la clasificación que se muestra aquí, y otros hacen una clasificación más general sin entrar en lo que llamaremos frameworks.
En principio el algoritmo o método, se puede clasificar en una de las siguientes tres grandes caterorias [1]. Como veremos mas adelante, esta clasificación se puede hacer, más o menos, independiente de la filosofía, aproximación o framework con el que se decida trabajar, aunque en unas aproximaciones respecto a otras predominen más un tipo de algoritmo (FR-NR-RR) que otro.
Full Reference QA
Full Referencia Quality Assessment Algorithms. En estos métodos el algoritmo tiene acceso a una versión completa y perfecta de la imagen/video original o de referencia, para ser comparada con la imagen/video de procesada o distorsionada. Debido a la gran cantidad de recursos que se requieren suelen ser utilizados para desarrollar algoritmos de procesamiento de imagen/video para su testeo en laboriatorio, y rara vez aparecen como aplicaciones de tiempo-real.
No Reference
En estos algoritmos no se tiene acceso a la imagen/video original o de referencia. Solo se dispone de la imagen/video procesado o distorsionado. Pueden ser utilizados en aplicaciones donde se necesite medir la calidad, puesto que consumen muchos menos recursos. La desventaja es que suelen ser menos precisos en sus predicciones de calidad o estar únicamente disañados para un subconjunto de imagenes/video (las que tengan un determinado defecto, o un solo formato de imagen/video, etc...)
Reduced Reference
En estos algoritmos, se dispone de cierta información sobre la imagen "perfecta" original o de referencia. Cada algoritmo define la información que necesita de la imagen/video de referenica para poder comparar con la misma (u otra) información extraida de la imagen/video procesado o distorsionado. Se suele utilizar un canal auxiliar (llamdado RR-Channel) para hacer llegar esta información de referencia al algoritmo de valoración de calidad. Este tipo de algoritmos son los más heterogeneos y son los que más dificilmente resulta clasificar respecto los framewoks, sobre los que hablamos a continuación.
Aproximaciones, Frameworks o Filosofías
Se observan tres tendencias, aproximaciones, frameworks o filosofías (como se quiera llamar) en lo que a la Valoración Objetiva de Imagen y/o Video en base a la forma de obtener un índice de calidad objetiva que se correlacione más o menos bien con las valoraciones subjetivas realizadas por los test presenciales. Estas son:
- Error Sensitivity
- Structural Distortion/Similarity
- Statistics of Natural Images
Los nombres de estos frameworks no están consensuados en la bibliografía aunque el del primero si se diferencia claramente por ser el más veterano y sobre el que más literatura se ha escrito y por tanto sobre el que más variedad existe. El segundo ya lleva unos años dando resultados y el tercero es el más incipiente de los tres, aunque no en el análisis estadísticio de imagenes y/o video de escenas naturales (abreviadamente Imagenes Naturales) sino en la aplicación de éstas a la valoración objetiva de calidad. No obstante, aunque de unos años a esta parte han aparecido los dos últimos framewoks, no quiere esto decir que no se estén produciendo nuevas aportaciones al primero actualmente.
Además, y recien salido del horno (Febrero 2006) está un nuevo framework (así clasificado según sus autores, habrá que ver su consolidación como tal) Visual Information Fidelity que surge de la unión de los dos últimos, y el cual sólo se ha desarrollado para imágenes y no para video, aunque sus autores están trabajando en esta linea (pasarlo a video en base a los modelos estadísticos de imagenes naturales para video).
Aunque en principio hay que centrarse en los métodos de valoración objetiva de video, no podemos obviar la literatura relacionada con las imágenes (sobretodo en los frameworks recientes), puesto que es en ésta donde se sientan las bases de muchas aproximaciones de video y donde se explica con más detalle las partes de análisis espacial que se utiliza en los algoritmos de vídeo (espacio-temporal) y que muchas veces solo aparece referenciada en el paper de video, pero sin un detalle en su explicación, por lo que hay que recurrir a los paper de imágenes donde lo explican mas.
Respecto a los tres métodos mencionados, FR, RR y NR en principio pueden admitir cualquiera de los frameworks, como digo, sin embargo, si es cierto que por la propia naturaleza de dichos frameworks y por su historia, puede que para alguno exista más literatura dentro de un método que en otros, e incluso no existir (de momento) literatura sobre un framework en alguno de los métodos. Por ejemplo, para el framework de Distorsión Estructural es más "natural" el método FR y la mayoría de lo encontrado son aplicaciones a Imagen, no a Video. El Framework de Sensibilidad de Errores, en las clasificaciones encontradas, se asocia casi únicamente con métodos Full-Reference, pero se puede extender a métodos NR si tenenmos en cuenta que muchos de estos últimos procesan defectos específicos producidos por un tipo de codificación de video, compresión o transmisión, y al fin al cabo el método resultante es sensible a estos errores, es decir, utiliza una comparación con errores en el cálculo del valor de la métrica. Los métodos RR que no son claramente pertenecientes a los otros Frameworks, los asociaremos a ESF, cuando utilicen la información adicional para detectar el error producido en la codificación por comparación o medición de los errores producidos en esta información adicional.
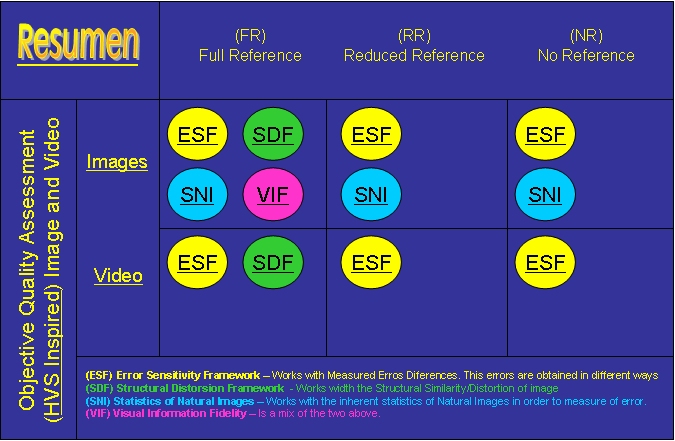
De esta forma, si a la clasificación por métodos (FR, RR y NR) le añadimos cada uno de los frameworks y distinguimos también por su aplicación a Imágenes o a Video con independencia del framework utilizado tendremos el cuadro organizativo del índice y del que aqui se muestra una imágen.
A continuación revisamos a grandes rasgos las características de cada una de estas aproximaciones. Para cada framework y cada método revisaremos las características más destacables de las métricas encontradas que encajen en la clasificación.
Error Sensitivity Framework
Métodos Full-Reference
La mayoría de las métricas de valoración de la calidad objetiva se situan en este marco de trabajo, que puede ser traducido como "Sensibilidad a Errores", y cuyo objetivo es cuantificar y clasificar los distintos errores que se detectan entre la imagen/video, con cualquiera de los métodos (FR,RR,NR), ponderandolos apropiadamente para ajustarse objetivamente, lo más posible, desde un punto de vista perceptual a la valoración subjetiva de los individuos que visionan las escenas distorsionadas.
Aunque cada una de las métricas o algoritmos que se ubican en este framework tiene particularidades, la mayoría de ellos se ajustan a un modelo o un esquema general de funcionamiento FR, que es el que se presenta a continuación y sirve para explicar dichas métricas y ubicar cada una de sus fases. Dado que el Framework se ha utilizado más extensamente con el méodo FR el esquema que vemos a continuación tiene en cuenta este método.
Esquema y Descripción
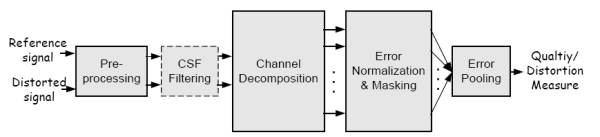
Los bloques que se muestran son los resulstantes de aplicar un modelo del HVS a los algoritmos de este Framework. Aunque existan diferencias estos son los pasos generales de la modelización HVS. De estos se presenta un resumen:
- Preprocesado
Alineamiento de referencia y distorsionada (correspondencia punto a punto entre referencia y distorsionada), transformación del espacio de color a uno que se adapte bien al HVS, calibración de dispositivos (paso a unidades de luminancia), filtrado PSF (low-pass filter simulando la PSF (Point Spread Function) de la optica del ojo) y adaptación a la luz (light adatptation, paso a estimulos de contraste).
En cuanto al alineamiento de las secuencias no la explican en los papers revisados, seguramente será una cuestión que surge en detalle a la hora de la implementación.
En cuanto a las transformaciones de espacio de color, Winkler_1999b realiza una conversión del espacio de color Y'Cb'Cr' definido en la ITU-R Recommendation 601 a un espacio de colores opuestos basandose pasando primero pasa a R'G'B' (RGB normalizado de 0 a 1). Luego pasa los componentes por una función no lineal para adaptarlo a la salida o comportamiento convencional de un display CRT. Luego, conociendo la sensibilidad de los conos del HVS y basandose en el modelo de color de [20,21] (en Winkler_1999b) obtiene los valores de los canales de color opuesto B-W (Black-White), R-G (Red-Green) y B-Y (Blue-Yelow). Watson_Hu_McGowan_2001 pasan a un espacio de color denominado YOZ donde Y es lumninancia en candelas/m2, O es un canal de color opuesto con una determinada matriz de conversión, y Z es el canal azul dado por al coordenada CIE Z. Esta transformación normalmente la realizan con una transformación gamma segida de una transformación lineal de color. Sin embargo, hay otros autores que no realizan transformaciones de color, incluso se quedan sólo con los datos de lumniancia para reducir el coste computacional de las métricas Yu_Wu_Winkler_Chen_2002, aunque si indican que si la precisción de la métrica es crítica se puede ampliar la métrica a crominancia, para lo que habría que hacer una transformación del espacio de color como en Winkler_1999b.
Otro preprocesamiento es el recorte o crop, que utilizan varios autores para eliminar el problema que surje al procesar los bordes de la imagen quedandose con la parte central, Watson_Hu_McGowan_2001, Yu_Wu_Winkler_Chen_2002, o anteriormente Winkler en Winkler_1999b (aunque en el paper no lo indica).
Otro de los pre-procesamientos es desentrelazar las secuencias de entrada, esto lo tienen en cuenta las métricas de Yu_Wu_Winkler_Chen_2002 y Watson_Hu_McGowan_2001 aunque este último no indica exactamente como lo realiza.
En cuanto a la simulación de la óptica del ojo existe una corriente de "foveización"; de la imágen, en la que procesan con distinta frecuencia espacial los puntos o zonas de interes de la imagen respecto al resto, emulando, con los parámetros adecuados el comportamiento de la visión foveal del ojo, donde la mayor sensibilidad tanto al color como a la frecuencia espacial se da en un único punto de la retina. Exiten artículos sobre esta aproximación, Wang_Bovik_Lu_2001 (utilizando wavelets) y no solo como preprocesamiento de la imagen sino como sistema completo de codificación de vídeo, Lu_Wang_Bovik_2002. El problema de este sistema es la asignación dinámica y automática de las zonas de interes.
No hay una definición universal de contraste para escenas naturales, algunos modelos [26] trabajan con bandas de contraste (band-limeted contrast) para escenas complejas (escenas naturales), lo que está muy relacionado con la descomposición en canales, por lo que los calculos de contraste pueden realizarse durante o tras la descomposición.
- Filtrado con Funciones de Sensibilidad de Contraste
CSF puede ser simulado antes de la descomposición en canales, con filtros que aproximen la respuesta en frecuencia de CSF a la respuesta espacio-temporal obtenida mediante experimentos psicofísicos o reportados en la literatura, como VanDenBrandenLambrecht_1996, o bien, como hacen otras métricas, implementan la CSF como factores de ponderación tras la descomposición en canales, multiplicando la salida de cada banda o canal por la sensibilidad de contraste de dicho canal como Yu_Wu_Winkler_Chen_2002. Es decir, esta etapa puede ir antes o despues de la descomposción en canales de frecuencia espacio-temporal y orientación. También estos valores por los que se multiplica salen de las funciones CSF modeladas en los experimentos psicofísicos.
- Descomposición en canales
Los canales sirven para separar los estimulos visuales en diferentes subbandas espaciales y temporales. Aunque algunos modelos utilizan una descomposición sofisticada utilzando los modelos vistos anteriormente, donde se establece un filtrado de la secuencia por orientación, frecuencia espacial y frecuencia temporal, dando lugar a un determinado número de bandas o canales que luego tienen que ser procesados para obtener las medidas de error. Aunque también las transformaciones simples como la DCT (Discrete Cosine Transform) o la trasformada wavelet son muy utilizadas por simplicidad a pesar de que no se ajusten bien al modelo cortical neuronal del HVS. Ver Diseño de filtros, descomposición en canales más arriba.
- Normalización de Errores y Enmascaramiento
Normalmente se implementan para cada canal. La mayoria de los modelos implementan el enmascaramiento como un mecanismo de control de ganancia que determina la señal de error del canal mediante un umbral de visibilidad variable en el espacio (con la posición) [33]. Explica como se implementa el enmascaramiento y como se utiliza la elevación de umbral (threshold elevation) para normalizar el error. Esta normalización se mide en unidades de Just Noticeable Difference (JND), Sarnoff_1997, donde 1.0 indica que la distorsion en un canal está en el umbral de la visibilidad. Otros métodos implementan el enmascaramiento como la respuesta a la saturación de contraste basandose en unas curvas de saturación que representan las del HVS.
- Ponderación de errores o Error Pooling
Es el mecanismo de combinar las diferentes señales de error de los distintos canales en una interpretación única de calidad/distorsión. La mayoria de los métodos utilizan la formula de Minkowski. Se puede procesar la formula sobre espacio y luego sobre frecuencia o viceversa e introducir no-linelidades. Algunos autores utilizan un mapa de "importancia espacial" de diferentes regiones para proporcionar variabilidad espacial en la ponderación.
Existen, dentro de la aproximación FR, otra serie de métodos que no siguen el esquema propuesto. Son aquellos que utilizan la técnica de Watermarking. Entre ellos tenemos Winkler_Gelasca_Ebrahimi_2003, que propone dos métricas para evaluar la calidad perceptual de los vídeos con watermarks, midiendo los dos artefactos principales que se observan debidos a la inclusión del watermark en la secuencia. Las métricas propuestas se basan en la obtención de un índice de calidad (uno para cada defecto) como diferencia entre el efecto observado en la secuencia original y la procesada.
Limitaciones del Error Sensitivity Framework
Según la clasificación de Wang_Sheikh_Bovik_2003, este framework es básicamente Full-Reference, aunque nosotros, como hemos dicho, ampliemos esta clasificación para incluir bajo el mismo nombre los NR y RR que se basan en detección de cualquier tipo de error.
Según Wang_Sheikh_Bovik_2003, el objetivo de este framework es predecir la calidad perceptual mediante la cuantificación de los errores perceptibles, mediante una simulación de los componentes funcionales del HVS relacionados con la percepción de calidad. Pero el HVS es extremadamente complejo.
La mayoria de los modelos de este framework hacen una serie de asunciones que enumera en el paper, y argumenta que en función de la aplicación del modelo estas asunciones pueden ser validas o razonables desde el punto de vista practico, pero que la mayoria de las asunciones son discutibles y deberían ser validadas.
Creen que existen numerosos problemas criticos para justificar la utilidad de este framework. Enumeran y argumentan los problemas por los que consideran esto. Y por tanto proponen el Framework de Distorsión Estructural.
- The Suprathreshold Problem. Cuestiona que tras la normalización y el enmascaramiento, la relación entre la magnitud del error y la distorsion percibida por el HVS pueda ser correctamente modelada para los casos en los que el error en un canal visual es mayor que el umbral de visibilidad. También cuestiona la utilización de un umbral de "just noticeable visual error" para normalizar los errores para los distintos canales.
- The Natural Image Compexity Problem. La mayoria de los experimentos psicofisicos se realizan con patrones relativamente simples, como rejillas sinusoidales, cuadros de Gabor, formas geometricas, etc.. Por ejemplo, las CSF son obtenidas de experimentos que utilizan patrones simples de frecuencia. Los experimentos de enmascaramiento normalmente incorporan dos o unos pocos patrones diferentes. Todo esto es muchisimo mas simple que la complejidad de las imagenes naturales.
- The Minkoswski Error Pooling Error.La formula de sumatorio de errores de Minkowski esta basada en las diferencias entre dos señales, pero esto no refleja las diferencias o cambios estructurales de estas señales.
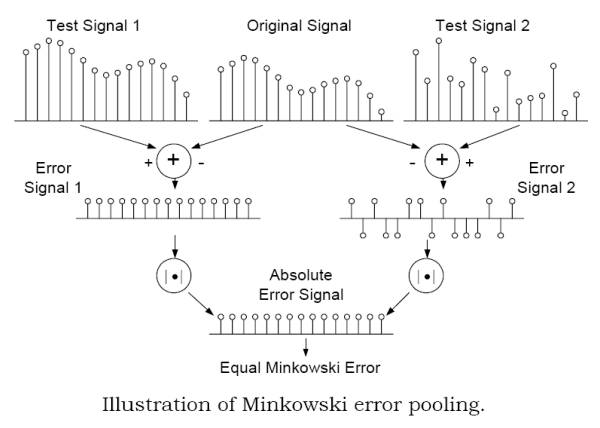
Con el ejemplo de la imagen (explicado en el paper) se ve que no solo es importante la preservación estructural de la señal sino que el test de Minkowski es ineficiente capturando la estructura de los errores y por tanto las metricas que la utilicen son metricas con perdida de información estructural "Structural Information Lossy Metrics". Aunque la metrica aplique una descomposición en frecuencia, si esta descomposición en frecuencia no es capaz de decorrelar la estructura de la imagen la metrica adolecera del problema. Es el caso de las descomposiciones lineales como la wavelet. Se ha demostrado [60,61] que existe una fuerte correlación entre los coeficientes wavelet intra- e inter- canal de imagenes naturales. De hecho sin explotar esta fuerte dependencia el estado del arte en la compresión de imagenes mediante wavelets [62,63,64] no tendrá exito.
- The cognitive Interaction Problem. El conocimiento cognitivo y el proceso visual activo (cambio de fijación) son importantes para el PVQA. Si el observador está instruido o no en las actividades [2,65], el conocimiento previo de la imagen, la atención y la fijación [2,66] resultara en una u otra calidad. Hay experimentos en los que la calidad simplemente se puntua diferene por la inclusión o no de sonidos del conferenciante o de fondo. Actualmente las metricas no tienen en cuenta estos procesos.
Métodos No-Reference
Las aproximaciones NR trabajann con la siguiente filosofía, Todas las imágenes y videos son perfectos, a menos que se distorsionen durante su adquisición, procesado o reproducción.
Por tanto la línea de NR se limitará a medir las distorsiones posibles introducidas en estas etapas. Unas soluciones estarán por tanto específicamente diseñadas para medir un cierto tipo de distorsiones provocadas en una o varias fases conocidas, aplicando mediciones del error introducido por estas distorsiones, es decir, miden la cantidad de distorsión que son capaces de percibir.
Otras soluciones hacen lo mismo pero sin tener en cuenta la fase en la que se introduce la distorsión, por lo que la medición de estos deféctos utiliza un método más generica por no contar con el conocimiento del tipo y características del error introducido específicamente en una fase del procesamiento de la imagen o vídeo. Normalmente la distorsión más considerada es la DCT-block introducida en la compresión con técticas DCT de bloque. Así pues, estas soluciones, específicas para esta distorsión, no medirán bien la calidad objetiva de otras secuencias que no se hayan procesado con este tipo de algoritmos, por ejemplo, si se utilizan wavelets el blockiness no aparece, por que la medida de calidad perceptual puede no ser ajustada.
Otro tipo de algoritmos NR, que hemos clasificado en el framework de Imágenes Naturales, son aquellos que consideran la imágenes naturales (o videos) como referencia perfecta. Estos métodos establecen un modelo estadístico que de dichas imágenes naturales (o videos) y se basan en la medida de las diferencias respecto a este modelo estadístico encontrado en la imagen/video procesado. Como se clasifican en otro framework sus características se explicarán en el apartado correspondiente.
Entre las soluciones específicas para vídeo (ver el review de Wang_Sheik_Bovik_2003 donde aparecen referencias también para imágenes) que se clasifican en este framework, tenemos a Marziliano_Dufaux_Winkler_Ebrahimi_2002 que establecen una métrica NR para cualificar el vídeo en base a la medición del efecto blur (enborronamiento) producido en los bordes verticales mediante la medición del ancho de éstos. Los bordes son detectados para cada frame mediante un algoritmo de detección de bordes. Para cada borde encontrado se establece su ancho localizan el máximo y el mínimo de luminancia entorno al borde detectado y midiendo su distancia. La métrica resultante viene de mediar el ancho de bordes acumulado dividido por el número de bordes procesados. Según tests subjetivos indican que la métrica se ajusta bastante bien. (Pero sólo mide uno de los efectos producidos en el proceso de captura, procesado, envío y representación de la secuencia de vídeo). Como vemos, esta métrica, a diferencia de las métricas FR no tiene en cuenta ningún aspecto morfológico o estructural del HVS, simplemente realiza mediciones de error respecto una característica determinada de la imágen o video.
Otras métricas en esta clasificación, entre ellas Cavallaro_Winkler_2004 se centran en la estimación de la calidad visual basándose en el análisis de los artefactos blockiness, blur y jerkiness encontrados en el vídeo. No mencionan cómo realizan la medición de estos defectos de la imágen (seguramente apliquen métodos que los autores hayan aplicado para imágenes), pero lo novedoso es que proponen añadir etapas posteriores que emulen el comportamiento cognitivo del HVS. Para ello a la métrica NR inicial (de la cual solo indican que pertenece a Genista Corporation) le añaden etapas que emulan las sacadas que modifican el foco de atención y etapas para el seguimiento de objetos móviles. Estas etapas son de segmentación semántica. Por ejemplo, la segmentación semántica que utilizan es la detección de caras en la escena mediante selección de patrones de crominancia para la piel humana unidos a unos detectores morfológicos o detectores de características faciales.
Turaga_Chen_Caviedes_2004 proponen una métrica estimativa del PSNR de un vídeo comprimido basándose únicamente en las propiedades estadísticas específicas que tienen los coeficientes de la compresión DCT. De forma que simplemente con el análisis estadístico de estos coeficientes y sin acceder al bitstream comprimido ni a la imágen de referenica pueden realizar una estimación del PSNR general del vídeo. Por tanto no se centran en ningún tipo específico de distorsión. Utilizan el conocimiento estadístico [10] (del paper) para determinar el error de cuantización producido, y en base a el y a que los coeficientes se distribuyen con una distribución Laplaciana de probabilidad, obtienen 64 distribuciones para cada bloque 8x8 que son parametrizadas. Esta estimación se utiliza para estimar el error de cuantización y posteriormente en base a éste el PSNR global.
Carli_Farias_Gelasca_Tedesco_Neri_2005 utilizan una tecnica de ocultación de información (Watermarking) para introducir una marca débil en zonas perceptualmente importantes de la imagen. Para estimar la importancia de las zonas de la imagen se basan en características perceptuales sabidas de captar la atención visual, como movimiento, contraste y color. El emisor introduce la marca en las zonas seleccionadas y el receptor la extrae de las mismas zonas. La degradación de la marca proporciona una medida de calidad de video. Los resultados muestran que su PSNRw mejora el PSNR genérico y que la medida de calidad propuesta crece monotonicamente conforme lo hace los indices subjetivos.
Por último, Hands_Bourret_Bayart_2005, aunque no explican con detalle la métrica NR utilizada para su algoritmo de mejora de la Calidad de Servicio de Video, presentan su esquema, del que hay que comentar que se trata de módulos específicamente diseñados como detectores para un algoritmo de compresión en concreto. Es decir, primero hay que conocer que algoritmo de compresión ha procesado la señal de entrada a los descriptores de calidad. Éstos realizan sus medidas en el tiempo, frame a frame, para posteriormente hacer de cada medida individual una agregación temporal (media) para 12 frames, ya que el HVS no tiene una resolución temporal tan fina. Por último aplica pooling para ponderar los pesos a aplicar. El valor de éstos pesos los ajusta mediante una regresión estadística de forma que el índice de calidad final se ajuste en mejor medida a índices de calidad subjetiva conocidos previamente.
Métodos Reduced-Reference
En estos métodos no se asume la disponibilidad completa de la señal de referencia, solo de información de referencia disponible a traves de canales de datos auxiliares. La figura muestra como un esquema de RR.
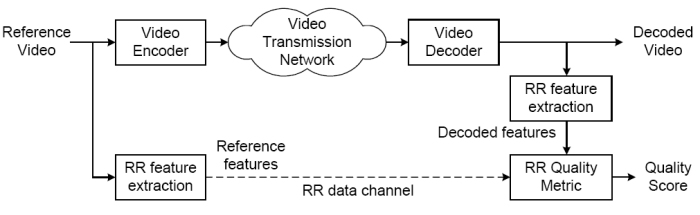
El diseño de metricas de calidad RR tiene que analizar cuál es la información relevante a transmitir por el canal RR.
Webster et al. propusieron la primera metrica RR en [71] basadas en la extracción de característics de actividad espacial y temporal. Se utilizan metricas para cada una de estas características (espacio-temporales). Estas características son transmitidas por el canal RR. Las metricas usadas son entrenadas con datos obtenidos de observadores humanos. El tamaño del canal RR depende del tamaño de las características extraidas.
Este trabajos se han extendido por Wolf_Pinson_1999 usando filtros de realce de bordes y extrayendo caracteristicas relevantes en una ventada 3D. Definen una metrica de alteraciones y reportan también resultados subjetivos. La métrica tiene el objetivo de evaluar las distorsiones espaciales a lo largo del tiempo. La imágen muestra el esquema de la métrica.
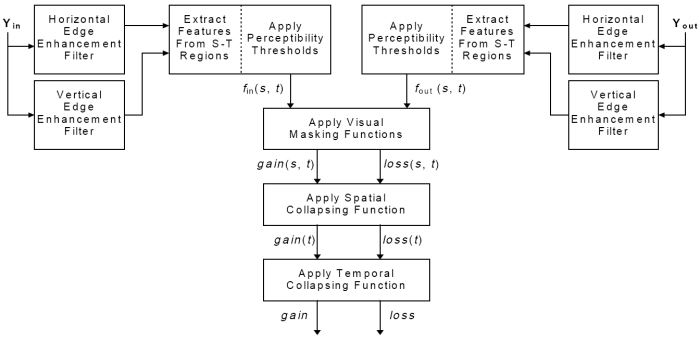
El algoritmo utilizado usa la componente de luminancia de la componente Rec.601 (Información comprimida por la ITU-R 601) de entrada y salida (señal Y de la Rec.601) se procesan con filtros de realce de bordes. Los video streams asi procesados se dividen en regiones S-T. De ellas se extraen las características que cuantifican la actividad espacial como función de la orientación angular. Se calculan las distorsiones de calidad comparando las ganancias y pérdidas de los valores obtenidos en las regiones S-T respecto la entrada y salida utilizando funciones que emulan el emnascaramiento. Se realiza pooling espacial y luego temporal sobre estas distorsiones para obtener el valor final de la métrica.
En Wolf_Pinson_2005 los autores modifican su métrica de la NTIA General VQM (FR) para adaptarla como una nueva métrica RR con un canal de referencia de menos de 10kbits/s. Ver resumen de este paper para más detalles.
Otra aproximación en Sugimoto_Kawada_Wada_Matsumoto_2001 ([73] en Wang_Sheikh_Bovik_2003) utiliza marcadores de bits ocultos en los frames enviados en el canal principal. También son enviados por el canal RR y una medida de la diferencia entre ambos se establece como indicador de perdida de calidad.
En Farias_Mitra_Carli_Neri_2002 ([74] en Wang_Sheikh_Bovik_2003) se utiliza la incrustación de una marca de agua "watermarking" en la imagen original y se sugiere que una perdida de calidad en la marca de agua indica una degradación medible en la calidad global del video.
Siendo estrictos estos últimos métodos anteriores no son realmente RR, pues no extraen información de la imagen, sino que añaden referencias cuya distorión medible en el destino lo interpretan como medida de calidad.
Structural Distortion/Similarity Framework
Descripción
Los autores del framework (Wang y Bovik) opinan que uno de los fallos fundamentales del Error Sensitivity Framework es que tratan a cualquier distorsión o variación de la imágen como un cierto tipo de error. La nueva filosofía en la creación de métricas sería:
The main function of the human eyes is to extract structural information from the viewing field, and the human visual system is highly adapted for this purpose. Therefore, a measurement of structural distortion should be a good approximation of perceived image distortion.
Se asume por tanto que el Human Visual System (HVS) no obtiene de la escena visual diferencia de intensidades y contrastes para percibir sino que extrae información estructural que procesará cognitivamente. Aunque es cierto que el procesmiento de la luminancia y contraste está implicito y forma parte del proceso por el que el HVS ve y es capaz de extraer dicha información estructural.
Proponen por tanto una nueva forma de abordar del diseño de métricas de calidad, basandose en el concepto de Similitud Estructural, o bien del concepto de medir la Distorsión Estructural. Para ello definen una nueva métrica en Wang_Bovik_2002 que posteriormente refinarán y ampliarán, pero que es la base de esta nueva aproxiación. También comentan que la métrica que ellos proponen no tiene porqué ser única. Todo depende de cómo se formule matemáticamente el concepto Diferencia Estructural, y que cualquier otra métrica formule de otra forma dicho concepto estaría dentro de este framework.
Podríamos pensar que un error en la imagen siempre va a suponer un cambio de estructura de ésta o al menos de los objetos afectados por el error, pero no todo lo que consideramos error en el Error Sensitivity Framework puede tomarse como un cambio de estructura. Por ejemplo, en dicho framework un cambio de luminancia es medido como un error en alguna de las fases de procesamiento y tenido en cuenta para la valoración final de la métrica, más o menos ponderdo. Aqui, los cambios de luminancia y contraste no son entendidos como modificaciones de la estructura de la imagen, puesto que las estructuras de los objetos de ésta no varían al hacerlo el contraste o la luminancia. Por tanto esta métrica distingue entre dos tipos de distorsiones, las que modifican la estructura y las que no.
Para entender mejor este nuevo framework, podemos situarnos en un espacio multidimensional donde todas las imágenes (de determinado tamaño), naturales o sintetizadas, se corresponden con un punto de dicho espacio, cuya ubicación en él viene determinada por un número de dimensiones igual al número de muestras (pixels, bloques, coeficientes, etc...) que se tengan de ellas. La imágen servirá para entender la intuición de la métrica.
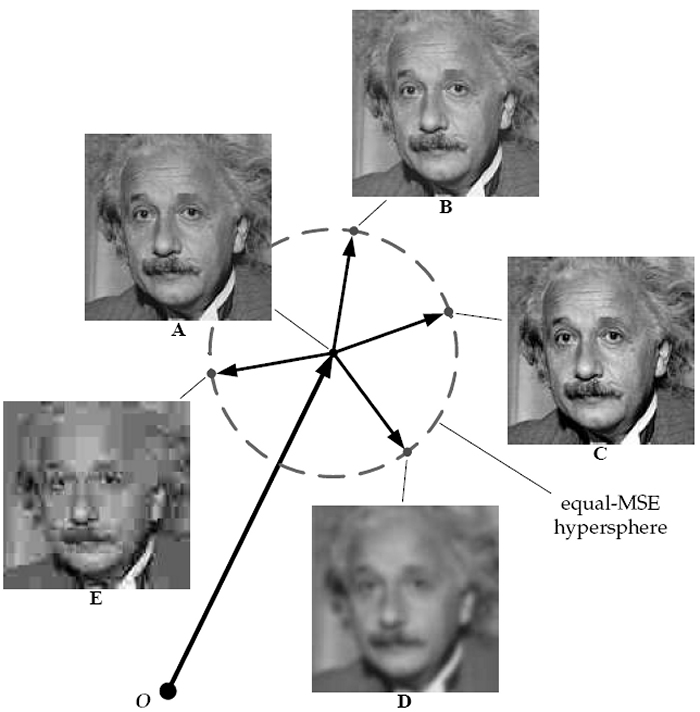
En este espacio multidimensional, a la imagen Origen (situada en el centro del circulo) que corresponde a la A se le pueden aplicar diferentes distorsiones, unas perceptualmente más destacables que otras, pero si todas ellas producen un mismo valor de MSE se situarán en el circulo cuyo radio será el valor del MSE en que se degrada la imagen original. La imagen muestra varias deformaciones, B y C son únicamente variaciones de luminancia y contraste respectivamente, mientras que C y D son blur y compresión JPEG. Claramente se observa que las variaciones únicamente de luminancia y contraste no afectan demasiado a la calidad perceptual de la imagen, mientras que las otras si. Por tanto no es importante, en este espacio de imagenes cuánto se varien las imagenes en modulo sino el tipo de distorsión que viene significado en el espacio por el angulo del vector de variación que se aplica a la imagen.
En otras palabras, desde el punto de vista perceptual o cognitivo, la cantidad de error por si sola no dice nada, hay que cualificar el "error" o variación como estructural o no. El valor absoluto de error o variación tendrá entonces distinto impacto perceptual sea la variación estructural o no.
Esto lleva a pensar en que las variaciones de luminancia y contraste no producen una distorsión en la estructura de los objetos de la escena sustancial, aunque son importantes y por tanto cuantificables y deben formar parte de la métrica final. Esto tiene un gran sentido físico, las variaciones de contraste y luminosidad no afectan la estructura física de los objetos. Asi que llegan a la conclusión que se debe de poder separar las variaciones que sufren las imagenes en variación de luminancia, de contraste y estructurales.
Comparacion con Error Sensitivity
En primer lugar el cambio de concepto, de medida de error a medida de la distorsión estructural. Aunque en muchos casos el error y la distorsión estructural pueden coincidir, en muchas circunstancias la misma cantidad de error puede deberse a diferencias significativas de distorsión estructural. Ponen como ejemplo una serie de imagenes alteradas con una variedad de distorsiones de forma que presenten aproximadamente el mismo valor MSE respecto al original.
Es interesante ver (Wang_Bovik_2002) como imagenes con la misma medida de error tienen grandes diferencias perceptuales de calidad. Sus pruebas subjetivas resultaron en que las distorsiones contrast stretch y mean shift proporcionan una calidad perceptual alta, mientras que las distrosiones blur y JPEG Compression tienen los valores de calidad perceptual mas bajos.
En segundo lugar, otra diferencia importante es que se considera la degradación de la imagen como pérdida percibida de información estructural. La imagen con mayor contraste tiene mejor indice que la comprimida simplemente porque la primera conserva toda la información estructural de la imagen original. Consideran una prediccion de calidad la medida de perdida de información estructural porque asumen que el HVS funciona igual, que se ha adaptado a extraer información estructural y detectar cambios en ella.
Y en tercer lugar, se usa una aproximación top-down que comienza con un nivel alto (intentando simular la funcionalidad hipotetica del HVS), mientras que la filosofía de sensibilidad a errores utiliza una aproximación bottom-up que intenta simular la función de cada uno de los componentes del HVS y combinarlos con la esperanza que el comportamiento sea similar al conjunto del HVS.
Como aplicar esta nueva filosofia es un tema abierto, dependera de como se interpreten y cuantifiquen los conceptos de "structural information" y "structural distortion". En lineas generales habría dos lineas.
Desarrollar un framework que describa las caracteristicas de las imagenes naturales y que la información estructural pueda compararse con la original.
Desarrollar un método de comparación de información estructural.
Una primera implementación en Wang_Bovik_2002.
Métodos Full Reference
Todos los métodos encontrados se basan en el Structural Similarity Index de Wang_Bovik_2002, pero con alguna variacíon para mejorar su eficacia, como el procesamiento multi-escala o foveal. Este método está basado en un indexador de distorsión, el cual se compone de tres factores,
- Perdida de correlación lineal entre la imagen original x y la distorsionada y
- Distorsión de luminancia, cuán diferente es la media de luminancia de x e y
- Distorsión de contraste, cuán diferentes son las varianzas de x e y.
Estos tres factores son los tres componentes de la ecuación (ver articulo para un desarrollo y explicación).
El primer factor es el coeficiente de correlación entre la imagen original y la distorsionada (x e y), que mide el grado de correlación lineal entre ellas y cuyo rango dinámico es [-1,1]. El mejor valor, 1, es obtenido cuando la correlación cumple la ecuación de la recta, siendo a y b constantes y a>0. Por tanto una transformación lineal de la imagen mantiene la información estructural, y un valor decreciente de este índice indica cuan no lineal es la transformación que se le aplica a la imagen. Aunque la original y la distorsionada esten correlacionadas linealmente pueden tener otras distorsiones. De esto se ocupan los otros dos factores del producto.
El segundo factor tiene un rango de [0,1] y mide cuan similares son los valores medios de luminancia de ambas imágenes. El valor 1 se obtiene si y solo si las medias son iguales.
El tercer factor mide cuan similares son los contrastes de ambas imágenes, con un rango de [0,1] alcanzando el 1 solo si los contrastes son iguales.
Las imagenes no son invariantes espacialmente, por lo que lo deseable es extraer estos estadísticos localmente y combinarlos. Ellos utilizan una ventana deslizante de tamaño BxB para ir calculando los estadísticos por la imagen desplazando la ventada de izquierda-derecha y arriba-abajo. La siguiente formula realiza la ponderación de los M pasos siendo Q_j el valor de cada aplicación de la ventana.
Pasa a analizar los resultados de aplicar este indice a imágenes de referencia con una ventana de B=8, obteniendo buenisimos resultados y segun sus tests subjetivos totalmente correlacionados con los valores de estos.
Nos redirigen a la web de Wang para ver más imagenes de muestra y para obtener una implementación en Matlab y C++ de este indice de indexación propuesto.
El índice propuesto (Q) es una implementacion rudimentaria de la nueva filosofía que aunque pronostica buenos resultados sobre los tests realizados se debe seguir investigando para enlazar con más elmentos del HVS, proponer mejores indices y optimizar el algoritmo.
Otro importante tema para explorar (a la fecha) es cómo aplicar este indice al video (PVQA). En Wang_Lu_Bovik_2004 se ha calculado el índice frame a frame para una secuencia de video y combinado con otras metricas de distorsión de imagenes como "bloking" para producir una metrica de calidad de video.
Ahora que conocemos la métrica inicial un poco más de cerca veremos que aportaciones han realizado en los sucesivos papers sobre ésta.
En Lu_Wang_Bovik_Kouloheris_2002 utilizan el nuevo índice para implementar un algoritmo FR para la valoración de calidad. La imagen muestra el modelo.
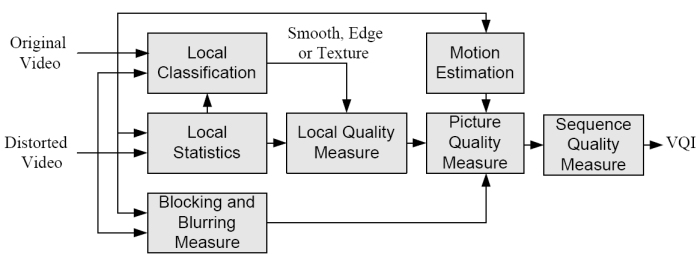
Primero miden la calidad frame a frame para por ultimo mediar los índices de calidad de los frames en el de la secuencia final. Sobre bloques 8x8 seleccionados aleatoriamente, no todos, se pasan primero analisis estadísticos como media y varianza para determinar si el bloque pertenece a una región smooth (suave, homogenea) a una región de bordes o a una región de textura, para despues aplican el Universal Quality Index al bloque (No explica porque se clasifican en tipos de bloque). Se median los indices de todos los bloques para dar la medida de calidad del frame.
Esta medida de calidad del frame se ajusta teniendo en cuenta dos factores. Blockiness y Motion.
El Blockiness del frame se mide por separado basandose en el algoritmo de Wang_Bovik_Evans_2000 donde también se estima el efecto blur. La medida de blockines se utiliza para ajustar (No dice cómo) el indice del frame si tiene muy alto indice de calidad pero también tiene un alto blockiness, lo que ocurre en frames con mucho movimiento en MPEG a un bit rate bajo.
Luego estiman el movimiento entre el frame y el anterior mediante un algoritmo de estimación de movimiento con una resolución de full-pixel. La razon de hacer esta estimación es que el los ojos son menos sensibles al efecto blur cuando hay gran movimiento. El ajuste (no dicen como) del índice del frame se hace en este caso, bajo indice de calidad, alto blur y bajo blockiness, lo que suele ocurrir en codificación MPEG en modo de reduced-resolution y a bajo bit-rate.
La metrica de cada frame tiene en cuenta los tres componenetes de color, Y, Cb y Cr a los que se aplica el algoritmo independientemente, y los resultados se pondenran linealmente como indica el paper. El indice final del frame se media con los demas frames para dar el índice de la secuencia.
Más adelante, en Wang_Lu_Bovik_2004 analizan el comportamiento de este algoritmo FR de calidad de video contra todos los modelos prestentados al VQEG-Phase I mostrando que con la aplicación del nuevo índice se obtienen ligeramente mejores resultados. Hay que tener en cuenta que entre los métodos presentados en esta fase del VQEG se eligió uno por la ITU para su estandarización Pinson_Wolf_2004.
Primero generalizaron el Universal Image Quality Index para convertirlo en el SSIM en Wang_Bovik_Sheikh_Simoncelli_2004, ver paper y capítulo para desarrollo (curioso que referencien en un paper del 2003 a uno del 2004).
La imagen muestra el sistema de valoración de calidad que utiliza SSIM, como métrica FR para determinar la calidad entre las imágenes x (referencia) e y (procesada). Básicamente el SSIM(x,y) es función de luminancia l(x,y), contraste c(x,y) y estructura s(x,y), con la adición de una serie de constantes para prevenir resultado inestables cuando los denominadores tienden a cero. Para una explicación detallada de cómo se calcula el índice y cómo se interpreta en un espacio multidimensional de imagenes las variaciones estructurales, de luminancia y contraste que sufren las imagenes, es mejor referirse al capitulo de libro que escribieron mejorando las explicaciones dadas en los papers, Wang_Bovik_Simoncelli_2005 en el libro Handbook of Image and Video Processing, 2nd Edition de Al Bovik.
En Wang_Simoncelli_Bovik_2003 mejoraron los resultados del propio SSIM (Structural SIMilarity), para hacerlo robusto a pequeños escalados, rotaciones y traslaciones de la imagen, simulando los pequeños movimientos que sufren los dispositivos de captura. La imagen muestra el modelo multi-escala utilizado.
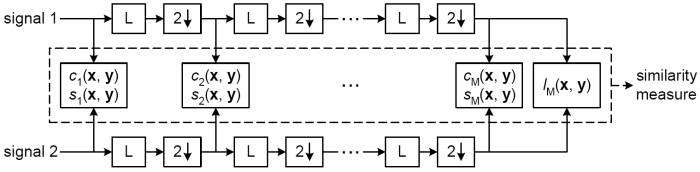
Se ve como inicialmente se realiza el calculo de las funciones de estructura y contraste para cada escala. Cada escala sufre un downsampling de 2 y un filtrado paso-bajo, tras la cual se vuelven a calcular las funciones mencionadas. Por ultimo se calcula la función de luminancia y con todos estos cálculos se obtiene la métrica final. Al utilizar una aproximación multiescala es necesario conocer los parámetros de ponderación o de importancia relativa de cada escala en el índice final. Para ajustar esos parámetros utilizaron una serie de imágenes sintetizadas para cada escala e incluyendo variaciones de luminancia, contraste y estfrucura. El conjunto de imágenes se presentó a un conjunto de observadores para obtener los índices subjetivos que sirvieron para parametrizar el modelo final. Para más detalles ver Wang_Simoncelli_Bovik_2003.
Posteriormente en Wang_Simoncelli_2005c realizan de nuevo una métrica invariante a pequeños escalados, rotaciones y traslaciones pero más barata computacionalmete utilizando distintas propiedades de los coeficientes Waveletes en el dominio complejo.
Por último Wang_Simoncelli_2005 han desarrollado un entorno para descomponer la distorsión entre dos imágenes en una combinación lineal de componentes. La descomposición no es fija como en descomposiciones como Fourier o Wavelet, sino que se adapta computacionalmete a las imágenes de entrada. Demuestran que este entorno matemático es una generalización de diferentes aproximaciones de comparación de imágenes. Como ejemplo de una implementación concreta utilizan el principio de Similitud Estructural de las imágenes, separando el conjunto de distorsiones en no estructurales y estructurales. Demuestran que la medida resultante es buena en la predicción de la calidad percibida por humanos.
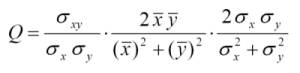
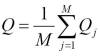
Statistics of Natural Images Framework
Descripción
Las imágenes y videos del entorno visual capturados con dispositivos de alta calidad operando en el espectro visual son clasificadas genéricamente como "Natural Scenes". Esto las diferencia de texto, escenas de gráficos generados por computador, animaciones, dibujos, ruido aleatorio, o imágenes y vídeos capturados de estímulos no visuales como Radar, Sonar, Rayos X, ultrasonidos etc...
Las escenas naturales forman un conjunto extremadamente pequeño de todas las posibles escenas, Ruderman_1994 y Field_1987.
Normalmente los métodos que utilizan las estadísticas de las imágenes naturales son NR. En los métodos NR existen muchos factores no cuantificables que juegan un papel importante en la valoración subjetiva de calidad, como son estética, relevancia cognitiva, conocimiento, aprendizaje, contexto visual, etc. Además estos factores son variables entre individuos. Sin embargo se puede trabajar con NR con la siguiente filosofía: Todas las imágenes y videos son perfectos a menos que se distorsionen durante su adquisición, procesado o reproducción. Por tanto la tarea de NR se limita a medir las distorsiones posibles introducidas en estas etapas. La referencia entonces, en un NR, son las estadísticas de imágenes naturales (y videos) medidas respecto a un modelo que mejor se ajuste a un tipo de distorsión o aplicación.
De esta forma todas las imágenes "perfectas" son tratadas por igual independientemente de su valor estético, Sheikh_Wang_Cormack_Bovik_2002 , Wang_Sheikh_Bovik_2002. En estas métricas se asume que las distorsiones de las imágenes son aquellas cuyas estadísticas se separan sustancialmente de las estadísticas de las "perfectas imágenes naturales". Por ejemplo, las imágenes naturales no contienen "bloking artifacts" y la presencia de una discontinuidad en bordes en las direcciones vertical y horizontal con un periodo de 8 pixels probablemente se deben a una distorsión introducida por una compresión block-DCT. Algunos aspectos del HVS como texturas y enmascaramiento de luminancia también se modelan. Por tanto las métricas NR no tienen que modelar sólamente el HVS sino las estadísticas de las imágenes naturales.
Cierto tipo de distorsiones como los "blocking artifacts" son fáciles para las NR. Otras no. La transformada wavelet se aplica a la imagen completa y no produce, por ejemplo, "blocking". Por tanto las metricas NR que se basen en "blocking artifacts" fallaran si el procesdo de la imagen distorsionada es uno u otro. Por tanto cada metrica NR deberá disañarse especificamente para un determinado tipo de imágenes objetivo.
Cuanto más sofisticado sea el modelo de las imagenes naturales mejor rendimiento tendrán las métricas NR siendo mas robustas a distintos tipos de distorsiones.
Las tres aproximaciones para el QA, SDF, ESF y SNI están conectados uno al otro mediante esta hipótesis: El proceso físico de formación de la imagen del entorno visual tridimensional deriva en determinadas propiedades estadísticas de los estímulos visuales, en respuesta a las cuales el sistema visual humano ha evolucionado. Los investigadores creen pues, que los estímulos visuales que emanan del entorno natural han dirigido la evolución del HVS, y que por tanto son problemas duales el modelado del HVS y el de las escenas naturales (Simoncelli_Olshausen_2001).
Se ha investigado mucho para entender la estrucutra de este subespacio de las imágenes naturales mediante el análisis de sus estadísticas y desarrollando modelos matemáticos de las imágenes naturales, Ruderman_1994, Field_1987, Simoncelli_1997b, Buccigrossi_Simoncelli_1999, Wainwright_Simoncelli_Wilsky_2001. Modelos que utilizan Principal Components Analysis (PCA) e Independent Component Analysis (ICA), y que incluyen estadísticas que atraen el foco de atención humano, han revelado similitudes intuitivas entre las estadísticas de las escenas naturales y la fisiología del sistema visual humano, Hancock_Baddeley_Smith_1992, VanHateren_VanDerSchaaf_1998, Reinagel_Zador_1999, [29]. También se han estudiado modelos de escenas naturales multiresolución, en el wavelet domain, que capturan las fuertes correlaciones no lineales existentes en las imágenes y que no pueden ser detectadas por métodos lineales, Simoncelli_1997b, Buccigrossi_Simoncelli_1999 y Wainwright_Simoncelli_Wilsky_2001. Algunos autores reivindican que la mayoría de las propiedades estadísticas de las imagenes naturales se pueden explicar por el modelo "dead leaves", que es un modelo de formación de imágenes donde los objetos se ocluyen unos a otros Lee_Mumford_Huang_2001. Srivastava_Lee_Simoncelli_Zhu_2003 proporciona un review de los avances en estadísticas de imágenes naturales, teniendo en cuenta dos aproximaciones, estudio de las probabilidades de las descomposiciones en frecuencia de las imágenes naturales (Fourier o Wavelet), y descubrimientos de los aspectos importantes de las imágenes al restringir el estudio a las imágenes naturales. A la vez hacen un análisis de la aplicación de estas estadísticas a análisis de texturas, clasificación de imágenes, compresión y eliminación de ruido.
El uso de las estadísticas de las imágenes naturales se ha aplicado en varios algoritmos de procesamiento de imágenes, algoritmos de compresión (Shapiro_1993, Said_Pearlman_1996, Buccigrossi_Simoncelli_1999), algoritmos de eliminación de ruido (Field_1987, Mihcak_Kozintsev_Ramachandran_Moulin_1999, Romberg_Choi_Baraniuk_2001), modelado de imágenes [36], segmentación de imágenes [37] y análisis y sínstesis de texturas (Portilla_Simoncelli_2000).
Métodos No Reference
Las características que determinan las distorsiones provocadas por los procesos de compresión y procesamiento de las imágenes (blocking, blur, etc...) se han incorporado a las métricas NR. Estas distorsiones tienen patrones estadísticos conocidos, de forma que en este framework las variaciones estadísticas que se alejen de las estadísticas de las imágenes naturales (o sus modelos) pueden determinarse fácilmente.
En Sheikh_Wang_Cormack_Bovik_2002 se usa un modelo estadístico de las imagenes naturales en el dominio wavelet usado para valoración de calidad de imágenes JPEG2000. Adaptan el modelo de comparación con las estadísticas naturales para incorporar el conocimiento a priori de las características estadísticas de las distorsiones provocadas por la compresión JPEG2000, para construir un modelo simplificado que caracteríze a dicho tipo de imágenes. Su modelo también simula el comportamiento estadístico de las imágenes naturales sin comprimir. De esta forma pueden realizar medidas del alejamiento estadístico de la imágen de su comportamiento natural, y poder hacer predicciones acerca de la calidad. Los resultados hacen intuir que la percepción de la distorsión y la calidad de las imágenes está relacionada con la "naturalidad" de estas. Esto también ha sido observado por [39] en la percepción de la "naturalidad" del color.
El modelo de Sheikh_Wang_Cormack_Bovik_2002 tiene una complejidad computacional baja, pues introduce una simplificación basada en los coeficientes marginales wavelets y reportan que para imágenes de 768x512 el algoritmo responde en 5 segundos y si éstos coeficientes ya están disponibles en el stream JPEG2000 este tiempo se reduce sustancialmente, incluso con su implementación no optimizada en Matlab, por lo que lo califican como muy eficiente computacionalmente. En cuanto a los resultados cualitativos, su modelo se ajusta con una correlación lineal de 0.92 al MOS realizado y con una desviacion estandar de 0.013. Según califican ellos, estan obteniendo resultados cerca del límite impuesto por la predicción útil debida a la variabilidad entre diferentes sujetos. Sin embargo detectan que el rendimiento se ve afectado directamente conforme aumenta la cantidad de detalles espaciales y texturas de la imágen. Están trabajando sobre una versión adaptativa espacialmente mediante la construcción de mapas de calidad y la introducción de pooling. También buscan modelos más sofisticados que caractericen a las imágenes naturales.
Métodos Reduced Reference
En Wang_Simoncelli_2005b los autores también utilizan un modelo de las estadísticas de los coeficientes wavelet de imágenes naturales. También utilizan en su modelo la distribución marginal de éstos coeficientes, (otras distribuciónes conjuntas más complejas pueden modelar también las imágenes naturales, ver Huang_Mumford_1999, pero hasta ahora básicamente se utiliza ésta como simplificación).
Utilizan una métrica de "distancia de información" entre distribuciones de probabilidad, Kullback-Leibler (KLD) para cuantificar las variaciones que se observan entre las distribuciones marginal de los coeficientes wavelet de las imágenes de referencia y las comprimidas (cuantizadas). En el emisor se puede disponer de ambas distribuciones, pero en el receptor, a menos que se envíe la imagen de referencia o su distribución marginal de coeficientes, no está disponible. Por tanto utilizan en el emisor un modelo matemático paramétrico, (Generalized 2-parameter Gausian Density Model ver referencias en el paper) para reconstruir mediante los parámetros del mismo la distribución de la imágen de referencia. El receptor calculará la distribución de la imagen que llega y reconstruirá el modelo de la distribución de coeficientes de la referencia basándose en los parámetros recibidos por el canal RR. El índice de distancia obtenido por KLD se ajusta matemáticamente con los indices subjetivos de calidad, reflejando una mejora respecto el estado del arte de facto dado por el SSIM y por modelo Lubin's Sarnoff.
Las ventajas de la métrica es que no asume ningún tipo predefinido de distorsión en la que basan en análisis de las distribuciones, es decir, funciona para cualquier distorsión, además es el método RR que menos informacíon de referencia envía al receptor, básicamente los parámetros del modelo de distribución y una estimación del error (ver paper para más detalles), además es fácil de implementar y computacionalmente eficiente, siendo además insensible a pequeñas traslaciones, rotaciones y escalados por utilizar la Steerable Pyramide como descomposición wavelet.
Aproximación Hibrida. Visual Information Fielity
Comparaciones de Métricas
Video Quality Expert Group
Lineas de Investigación
Apendice I : HVS e Implicaciones en PVQA
Optica del ojo
La imagen en la retina es una versión distorsionada del estimulo visual. Se producen varias distorsiones que se pueden modelar para adaptar los algoritmos lo mas fielmente posible a la realidad del HVS (Human Visual System).
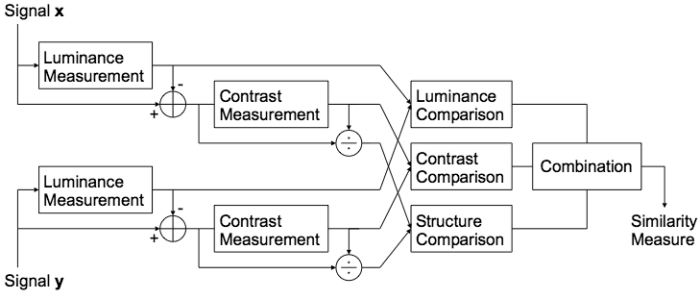
La mas significativa es el "blur" (suavizado, desenfoque). Para modelarla se utiliza una "PSF" o "LSF" (Point Spread Function, o Line Spread Function) que es la imagen que se forma en la retina ante un estímulo en forma de punto o de línea, cuya transformada de Fourier es la "modulation transfer function" del ojo para dicho estímulo. El grado de spreading (bluring, desenfoque) de este estímulo punto es una medida de la calidad de un sistema optico. La imagen muestra la propuesta de [128] en Winkler_1999
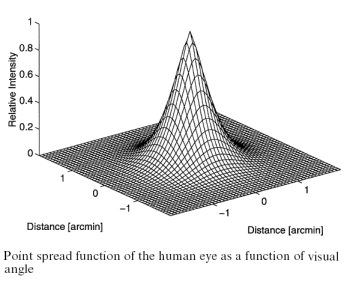
Estas PSF varian en su "ancho" con la apertura del iris y son la base de la visión foveal. La mayor agudeza está en el centro de la PSF. También varian con la distancia del objeto y con la longitud de onda. Por tanto cuando se focaliza una longitud de onda (un color) los demás no se perciben con la misma nitidez (Chromatic Aberration).
Hasta Winkler_1999 no había metricas que modelaran la aberración cromatica, mientras que la mayoria implementa la PSF como un suavizado antes de los demás procesamientos. Ver Descripción y Esquema General del Error Sensitivity Framework más adelante. Otros autores argumentan que este suavizado se pueden obtener de igual forma con las CSF (Contrast Sensitivity Functions) en etapas posteriores, pero entonces se ignora la forma de la función de transferencia y su variación con la longitud de onda.
Fotoreceptores y Vision Foveal/Periferica
Los fotoreceptores (conos y bastones) están distribuidos (simplificadamente) como un mosaico en la retina. Los bastones encargados de la visión con poca luz se encuentran dispersos en la retina. Esta dispersión aumenta conforme se alejan de la fovea (punto focal de la proyección de los estímulos sobre la retina, punto de máxima nitidez, resolución espacial). En esta únicamente existen conos, encargados de la visión con mucha luz. Sus tres tipos (L,M,S) responden a diferentes longitudes de onda (colores).
La distribución dispersa de los conos y bastones en la retina y la concentracíon de conos en la fovea, junto con el suavizado producido por la PSF conforman la visión foveal y periferica, modelada en [19, 20] de Wang_Sheikh_Bovik_2003. Image foveation es el proceso de muestreno no uniforme de la imagen que concuerda con la forma de adquisición de información en la retina. Aunuqe la mayoría de los modelos del HVS utilizados para métricas de calidad descartan la excentricidad de los fotoreceptores y se centran en la fovea (la distribución es uniforme simplifica el modelado), algunos re-muestrean la imagen con la densidad de fotoreceptores de la fovea reduciendo así la densidad de información visual, eliminando las altas frecuencias de regiones perifericas, manteniendo no obstante buenos indices de calidad.
En [20] de Wang_Sheikh_Bovik_2003 se utiliza una metrica basada en visión foveal sobre un aproximación Wavelet, Foveated Wavelet Image Quality Index (FWQI) que es utilizada sobre regiones de interes en [2].
Percepción del color
Las tasas de absorción de los distintos conos se separan en señales diferentes en fases tempranas del HVS generando señales independientes, lo que unido a que existe un solape en la sensibilidad a las longitudes de onda por parte de los conos L y M se obtiene que distintos tonos (hues) son procesados juntos mientras que otros nunca pueden ir unidos. Esto conforma la teoria de los colores opuestos apoyada por experimentos psicofísicos y psicologicos. Los componentes principales de el espacio de colores opuestos son el B-W (Black-White), R-G (Red-Green) y B-Y (Blue-Yellow).
Existen modelos y metricas que utilizan esta teoría [110,120] en Winkler_1999 aunque ya son un poco antiguas, habría que ver si estos artículos son citados mas recientemente.
Alternativamente se pueden usar otros espacios de color, CIE l*u*v y CIE l*a*b que fueron definidos con la intenciónn de poder medir la diferencia en la percepción de color, lo que es una ventaja para modelos PVQA como [67,141,142] en Winkler_1999
Las diferencias entre sistemas PVQA basados unicamente en luminancia frente a otros con el espacio completo de color son muy sutiles [111] en Winkler_1999, lo que explicaría que no haya encontrado mucho sobre PQA y color, habría que hacer una búsqueda específica sobre esto y sobre los que utilicen el modelo de color YCbCr que es el recomendado por la ITU-R Recomendation 601.
Adaptación a la luz y Sensibilidad al Contraste
La retina no codifica los valores de intensidad o luminancia directamente, sino que lo que codifica son las diferencias, es decir, el contraste del estimulo visual.
La sensibilidad al contraste está modelada como la inversa del umbral de contraste (nivel de contraste a partir del cual se empieza a percibir diferencia en el patron estímulo) mediante las funciones de Contrast Sentitivity Functions que representan la sensibilidad al contraste que se producen en las celulas ganglionares de la retina a medida que la frecuencia espacial varia en un estimulo formado por barras blancas y negras. En la imágen de la izquierda se observa que existe una frecuencia óptima para la cual las celulas tienen una mayor sensibilidad al contraste, es decir baja el umbral a partir del cual se percibe el contraste, sube la sensibilidad.
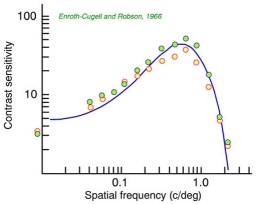
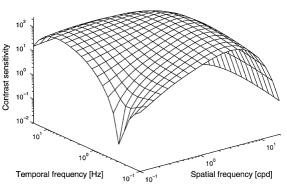
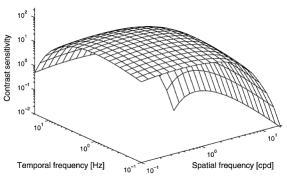
La sensibilidad al contraste además depende de la frecuencia temporal. En la imagen central vemos como teniendo en cuenta solo la luminancia pero también la frecuencia temporal la curva se convierte en un plano donde vemos como cae conforme aumenta la frecuencia espacio-temporal. Además para cada canal de color la función varia (imagen derecha), por lo que somos mas sensibles al contraste en función del color.
Para la utilización de estas funciones CSF en la PQA hay que tener en cuenta como implementar dichas funciones y para ello se puede optar por varios modelos, que disienten entre si en si son o no seperables las funciones en cuanto a frecuencia-tiempo. Además hay que determinar si se tendrán o no en cuenta los micromovimientos oculares ya que las funciones CSF son sensibles a éstos, existiendo algunos trabajos que los modelan en sus funciones.
Los algoritmos PVQA que incorporan las CSF lo hacen básicamente de dos formas. Una estableciendo la ganancia del filtro en cada banco en un entorno multicanal (ver esquema error sensitivity framework) de forma que se obtengan resultados parecidos a los experimentos psicofísicos. La segunda es prefiltrar cada canal (Luminancia B-W, R-G, B-Y) con su función CSF y calibrar o normalizar las siguientes fases. El primero es mas eficiente computacionalmente pero el segundo se ajusta mas al HVS y sus funciones CSF.
Aunque las aproximaciones de las funciones CSF utilizadas en los sistemas PVQA [21,66] en Winkler_1999 y en [21,22,23,24] de Wang_Sheikh_Bovik_2003 se aproximan bastante a los experimentos psicofisicos y psicologicos con parches de Gabor, todavía no se ha definido las funciones CSF para patrones o estímulos mas complejos como las imágenes naturales.
Enmascaramiento Espacial y Temporal / Facilitación
El enmascaramiento y su contrario, la facilitación como características del HVS, describen las interacciones relativas entre estimulos visuales. El enmascaramiento es el efecto de dejar de apreciar un estimulo por la inclusión de otro estímulo. La facilitación es el efecto de apreciar un estímulo que por si solo no lo es por la inclusión de otro estímulo.
En QA se asimila el ruido producido por la codificación como enmascaramiento o facilitación. El enmascaramiento/facilitación explican porque ciertas distorsiones introducidas por la codificación/compresión se aprecian mas en unas regiones de la imagen que en otras. Normalmente el efecto del enmascaramiento en general es mayor cuando el contenido en frecuencia y orientación entre máscara y estímulo (imagen) son similares, aunque experimentos psicofísicos demuestran que se producen enmascaramientos entre canales de distinta orientación, o entre canales de distinta frecuencia e incluso entre canales de luminancia y crominancia. Existen dos tipos de enmascaramiento, el espacial y temporal (ver Winkler_1999 para una descripción de ambos). En Winkler_1999b también se hace una descripción bastante clara del enmascaramiento (en el apartado de control de ganancia).
Mecanismos Espaciales y Temporales del HVS
Normalmente los mecanismos de percepción espaciales y temporales del HVS se modelan como un filtro o un conjunto de filtros que se aplican en un momento dado, según el esquema o aproximación que se utilice (ver Esquema del Error Sensitivity Framework) a la imágen/video originales o de referencia para simular esta percepción por los sistemas PVQA.
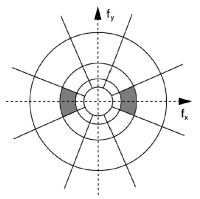
Por ejemplo, en cuanto a la percepción espacial, las "simple cells" son neuronas del primary visual cortex que tienen un campo receptivo compuesto por bandas o regiones excitatorias e inhibidoras alargadas y con orientación, como muestra en la figura y que actuan como filtros paso banda con una determinada orientación respondiendo a un conjunto de frecuencias y orientaciones relativas a su valor central. Todavia se discute acerca de la distribución exacta en el HVS (forma exacta y ancho de banda). Distintos experimentos psicofisicos dan distintos resultados.
También el estudio de las estadísticas de imagenes naturales aportan las mismas conclusiones y hablan de las frecuencias espaciales, la separacion en canales y las distintas orientaciones. Hay pocos resultados sobre la distribución espacial de los canales cromaticos. Se estima que el ancho de banda para la frecuencia espacial debe ser similar, pero se ha descubierto que el ancho de banda para las distintas orientaciones es mayor, es decir, hay un abanico mayor de orientaciones a las que responde el HVS para la crominancia.
Pero por razones de implementación la distribución y orientación de los filtros espaciales suele ser la misma para canales cromaticos y acromaticos en los distintos modelos de PVQA. En la figura se muestra un ejemplo ([131,132] en Winkler_1999) de como se particiona el espacio de frecuencias por el autor. En concreto utiliza tres bandas de frecuencia y cuatro orientaciones.
Los mecanismos temporales del HVS también han sido estudiados, aunque con menor acuerdo que los espaciales. Actualmente las teorias predominantes indican la existencia de dos canales llamados "sostenido" y "de transición" (paso-bajo y paso-banda). Experimentos psicologicos confirman estos hallazgos. En en Winkler_1999 habla sobre las frecuencias de estos canales y muestra el modelo de Fredriksen y Hess basado en derivadas de la funcion de impulso. En cuanto a la aplicación de mecanismos temporales no he encontrado mucho, será cuestión de buscar focalizando en esto.
Diseño de Filtros, descomposición en canales
Para diseñar métricas basadas en el modelo de sensibilidad a errores (ver Esquema del Error Sensitivity Framework), se suelen incorporar los elementos del HVS vistos anteriormente como un banco de filtros, en cuyo diseño deben de incorporarse la localización espacial, la frecuencia espacial y la orientación, para que se aproxime a los canales de frecuencia y orientación del HVS.
El diseño de este banco de filtros es variable por autores y es la parte más compleja y de difícil ajuste como modelo del HVS. Desde un punto de vista práctico y de implementación se ha utilizado una estructura piramidal utilizada por varios autores. Por ejemplo la Transformada Cortex de Watson Watson_1987 y modificaciones realizadas por Daly empleadas en QA [21] en Winkler_1999. Simoncelli propuso en [90,100] en Winkler_1999 otra organización de este banco de filtros, su llamada su Steerable Pyramide que es una descomposición de la imagen multi-escala y multi-orientación, invariante a traslaciones y rotaciones del estímulo, no tiene efecto aliasing y es auto-invertible. Otros autores Teo_Heeger_1994 utilizan otras aproximaciones. En general existen muchas variaciones respecto al diseño de este banco de filtro, por lo que habría que profundizar en su estudio si nos oritentamos por esta linea. Esto en cuanto a filtros espaciales. Para el diseño del banco de filtros temporal se utilizan filtros IIR (Infinite Impulse Response) que aseguran un delay de solo unos pocos frames, como en [62] en Winkler_1999 y en Wikler_1999b, frente a los filtros FIR (Finite Response Filters) que aunque tienen un delay de unas docenas de frames son más simples de implementar.
Los canales producidos por estos bancos de filtros, sirven para separar los estimulos visuales en diferentes subbandas espaciales y temporales. Aunque algunos modelos utilizan una descomposición sofisticada, las transformaciones simples como la DCT (Discrete Cosine Transform) o la trasformada wavelet son muy utilizadas por simplicidad aunque no se ajusten bien al modelo cortical neuronal del HVS.
Adaptación a patrones
La adaptación de patrones es el efecto que se produce por el ajuste de sensibilidad al contraste del sistema visual en respuesta a la estimulación continua con un patron de determinada frecuencia. Esto puede lleva a perdida de sensibilidad de contraste alrededor de dicha frecuencia. Este efecto, junto con el enmascaramiento ha llevado al modelode multiresolución.
La arquitectura multiresolución no tienen en cuenta otros aspectos temporales de la adpatación a patrones y estas caracteristicas deben ser introducidas a parte en el modelo. Diversos autores han proporcionado modelos que tienen en cuenta la adaptación a patrones, como son Webster y Miyahara [123] (en Winkler_1999) que con escenas naturales y enfoques lejanos y cercanos a los que adaptarse muestran una perdida de sensibilidad en frecuencias bajas-medias. También Webster and Mollon [124] (en Winkler_1999) hacen un estudio de la adpatación a patrones cromaticos en las escenas naturales.
Pooling
El pooling es la integración de la información proveniente de los distintos canales en el area V2 del cerebro. No se tienen evidencias concretas todavía de como se realiza esto, además parece ser que el proceso cognitivo tiene bastante que ver en esto. En resumen, esta ponderación de la información de los distintos canales debe hacerse para obtener un valor único para la metrica de calidad. Para las aproximaciones matemáticas a este proceso, como la suma de probablidadaes y el sumatorio de Minkoswki, que son los más utilizados, no se tienen todavía evidencias psicofísicias o psicologicas todavía que las corroboren.
El pooling debe realizarse para los canales espaciales y luego temporales o viceversa, se pueden introducir no-linealidades al proceso de ponderación y algunos autores introducen lo que llaman mapas de "importancia espacial" o "mapas de distorsión" de las distintas regiones para proporcionar esa variabilidad en la ponderación [31,34,35] (en Wang_Sheikh_Bovik_2003) y en .
Proceso Cognitivo
Hay componentes del proceso cognitivo humano que deben de tenerse en cuenta en los sistemas PVQA, como son el desplazamiento voluntario o "instintivo" del foco de atención y la capacidad de seguimiento de objetos móviles. Aunque el posicionamiento del punto de atención es inherente al individuo, grupos de individuos (en función del contenido de la escena) focalizan las mismas regiones de la escena. Maeder et al. [70] (en Winkler_1999) proponen la construcción de un mapa de interes basandose en factores como la intensidad de los bordes, energía de las texturas, variaciones de contraste y color, homogeneidad, etc. El seguimiento de objetos reduce la agudeza visual con la que se procea el fondo y de objetos que se muevan en otras direcciones. Una adaptacón de las funciones CSF pueden ser un primer paso en el modelado de este fenomeno [22,127] (en Winkler_1999)

Bibliografía:
[1]
LIVE Website
Laboratory for Image & Video Engineering
[2]
[Wang_Bovik_Lu_2001]
Foveated Wavelet Image Quality Index